10. Storage¶
The Storage section of the web interface allows configuration of these options:
- Swap Space: Change the swap space size.
- Pools: create and manage storage pools.
- Snapshots: manage local snapshots.
- VMware-Snapshots: coordinate OpenZFS snapshots with a VMware datastore.
- Disks: view and manage disk options.
- Importing a Disk: import a single disk that is formatted with the UFS, NTFS, MSDOS, or EXT2 filesystem.
- Multipaths: View multipath information for systems with compatible hardware.
10.1. Swap Space¶
Swap is space on a disk set aside to be used as memory. When the FreeNAS® system runs low on memory, less-used data can be “swapped” onto the disk, freeing up main memory.
For reliability, FreeNAS® creates swap space as mirrors of swap partitions on pairs of individual disks. For example, if the system has three hard disks, a swap mirror is created from the swap partitions on two of the drives. The third drive is not used, because it does not have redundancy. On a system with four drives, two swap mirrors are created.
Swap space is allocated when drives are partitioned before being added to a vdev. A 2 GiB partition for swap space is created on each data drive by default. The size of space to allocate can be changed in in the Swap size in Gib field. Changing the value does not affect the amount of swap on existing disks, only disks added after the change. This does not affect log or cache devices, which are created without swap. Swap can be disabled by entering 0, but that is strongly discouraged.
10.2. Pools¶
is used to create and manage ZFS pools, datasets, and zvols.
Proper storage design is important for any NAS. Please read through this entire chapter before configuring storage disks. Features are described to help make it clear which are beneficial for particular uses, and caveats or hardware restrictions which limit usefulness.
10.2.1. Creating Pools¶
Before creating a pool, determine the level of required redundancy, how many disks will be added, and if any data exists on those disks. Creating a pool overwrites disk data, so save any required data to different media before adding disks to a pool.
Go to and click ADD. Select Create new pool and click CREATE POOL to open the screen shown in Figure 10.2.1.
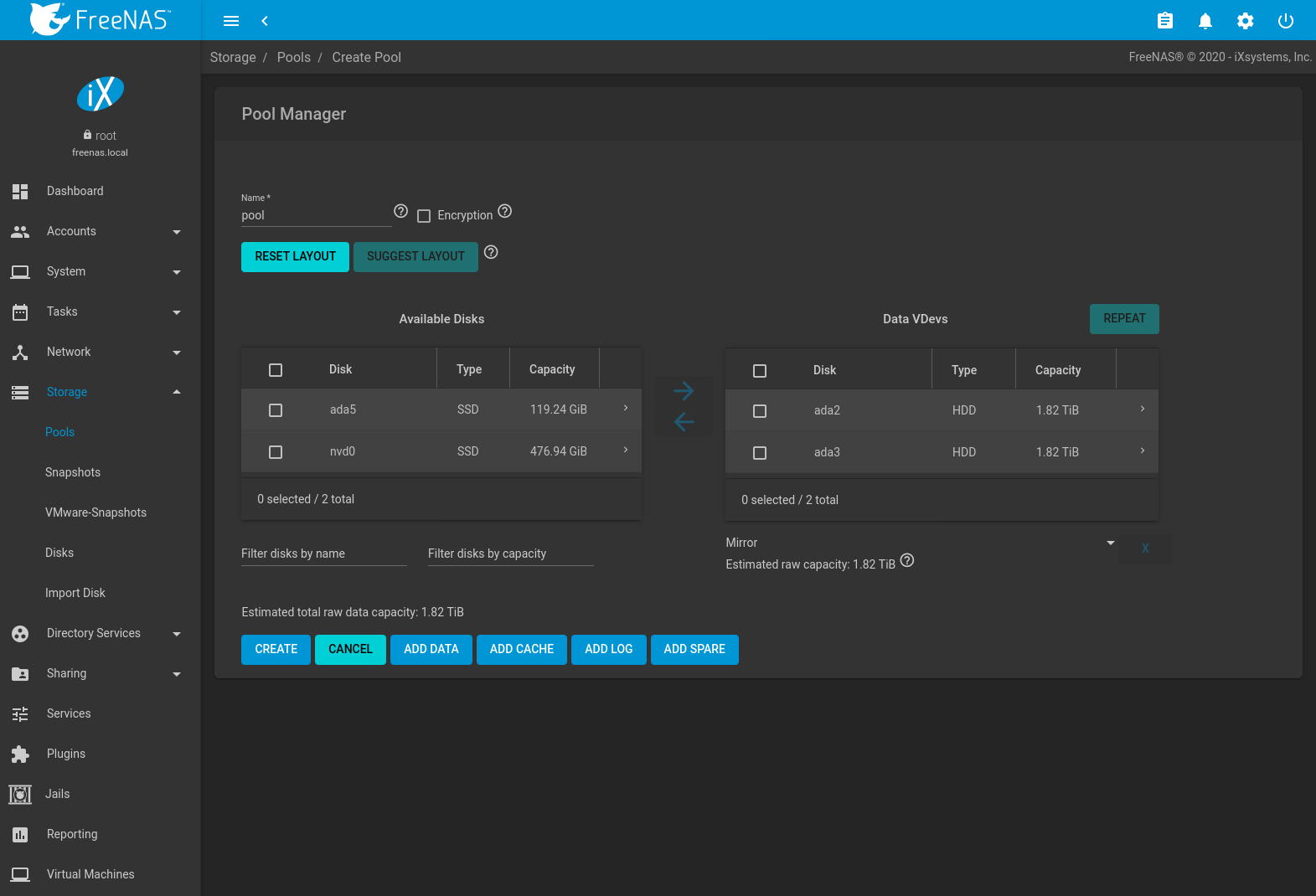
Fig. 10.2.1 Creating a Pool
Enter a name for the pool in the Name field. Ensure that the chosen name conforms to these naming conventions. Choosing a name that will stick out in the logs is recommended, rather than generic names like “data” or “freenas”.
To encrypt data on the underlying disks as a protection against physical theft, set the Encryption option. A dialog displays a reminder to back up the encryption key. The data on the disks is inaccessible without the key. Select Confirm then click I UNDERSTAND.
Warning
Refer to the warnings in Managing Encrypted Pools before enabling encryption!
From the Available Disks section, select disks to add to the
pool. Enter a value in Filter disks by name or
Filter disks by capacity to change the displayed disk order.
These fields support
PCRE regular expressions
for filtering. For example, to show only da and nvd disks in
Available Disks, type ^(da)|(nvd) in
Filter disks by name.
Type and maximum capacity is displayed for available disks. To show the disk Rotation Rate, Model, and Serial, click (Expand).
After selecting disks, click the right arrow to add them to the Data VDevs section. The usable space of each disk in a vdev is limited to the size of the smallest disk in the vdev. Additional data vdevs must have the same configuration as the initial vdev.
Any disks that appear in Data VDevs are used to create the pool. To remove a disk from that section, select the disk and click the left arrow to return it to the Available Disks section.
After adding one data vdev, additional data vdevs can be added with REPEAT. This creates additional vdevs of the same layout as the initial vdev. Select the number of additional vdevs and click REPEAT VDEV.
RESET LAYOUT returns all disks to the Available Disks area and closes all but one Data VDevs table.
SUGGEST LAYOUT arranges all disks in an optimal layout for both redundancy and capacity.
The pool layout is dependent upon the number of disks added to Data VDevs and the number of available layouts increases as disks are added. To view the available layouts, ensure that at least one disk appears in Data VDevs and select the drop-down menu under this section. The web interface will automatically update the Estimated total raw data capacity when a layout is selected. These layouts are supported:
- Stripe: requires at least one disk
- Mirror: requires at least two disks
- RAIDZ1: requires at least three disks
- RAIDZ2: requires at least four disks
- RAIDZ3: requires at least five disks
Warning
Refer to the ZFS Primer for more information on redundancy and disk layouts. When more than five disks are used, consideration must be given to the optimal layout for the best performance and scalability.It is important to realize that different layouts of virtual devices (vdevs) affect which operations can be performed on that pool later. For example, drives can be added to a mirror to increase redundancy, but that is not possible with RAIDZ arrays.
After the desired layout is configured, click CREATE. A dialog shows a reminder that all disk contents will be erased. Click Confirm, then CREATE POOL to create the pool.
Note
To instead preserve existing data, click the CANCEL button and refer to Importing a Disk and Importing a Pool to see if the existing format is supported. If so, perform that action instead. If the current storage format is not supported, it is necessary to back up the data to external media, create the pool, then restore the data to the new pool.
Depending on the size and number of disks, the type of controller, and whether encryption is selected, creating the pool may take some time. If the Encryption option was selected, a dialog provides a link to Download Recovery Key. Click the link and save the key to a safe location. When finished, click DONE.
Figure 10.2.2 shows the new pool1.
Select the pool to see more information. The first entry in the list represents the root dataset and has the same name as the pool.
The Available column shows the estimated storage space before compression. The Used column shows the estimated space used after compression. These numbers come from zfs list.
Other utilities can report different storage estimates. For example, the available space shown in zpool status is the cumulative space of all drives in the pool, regardless of pool configuration or compression.
Other information shown is the type of compression, the compression ratio, whether it is mounted as read-only, whether deduplication has been enabled, the mountpoint path, and any comments entered for the pool.
Pool status is indicated by one of these symbols:
| Symbol | Color | Meaning |
|---|---|---|
| HEALTHY | Green | The pool is healthy. |
| DEGRADED | Orange | The pool is in a degraded state. |
| UNKNOWN | Blue | Pool status cannot be determined. |
| LOCKED | Yellow | The pool is locked. |
| Pool Fault | Red | The pool has a critical error. |
There is an option to Upgrade Pool. This upgrades the pool to the latest ZFS Feature Flags. See the warnings in Upgrading a ZFS Pool before selecting this option. This button does not appear when the pool is running the latest version of the feature flags.
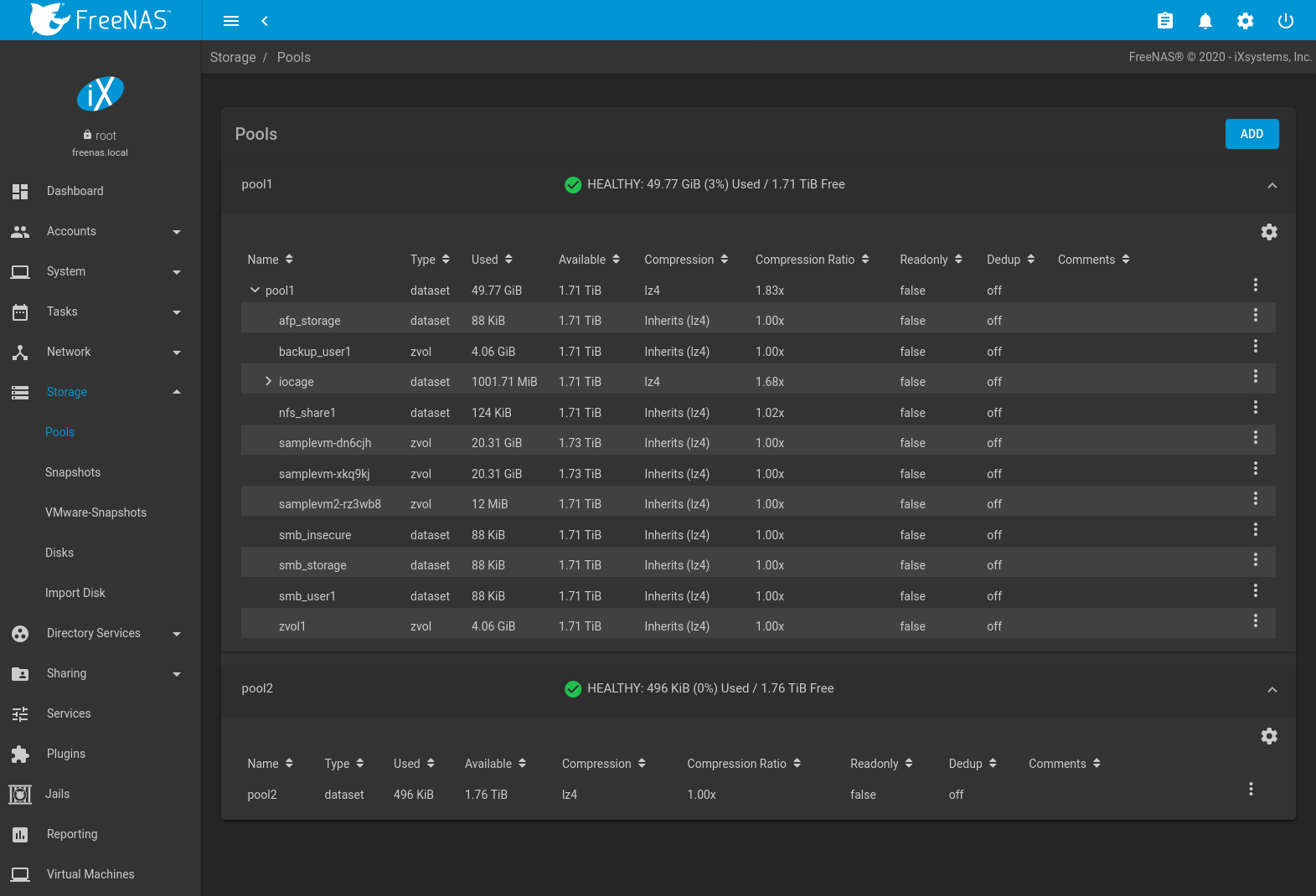
Fig. 10.2.2 Viewing Pools
Creating a pool adds a card to the . Available space, disk details, and pool status is shown on the card. The background color of the card indicates the pool status:
- Green: healthy or locked
- Yellow: unknown, offline, or degraded
- Red: faulted or removed
10.2.2. Managing Encrypted Pools¶
FreeNAS® uses GELI full disk encryption for ZFS pools. This type of encryption is intended to protect against the risks of data being read or copied when the system is powered down, when the pool is locked, or when disks are physically stolen.
FreeNAS® encrypts disks and pools, not individual filesystems. The partition table on each disk is not encrypted, but only identifies the location of partitions on the disk. On an encrypted pool, the data in each partition is encrypted. These are generally called “encrypted drives”, even though the partition table is not encrypted. To use drive firmware to completely encrypt the drive, see Self-Encrypting Drives.
Note
Processors with support for the AES-NI instruction set are strongly recommended. These processors can handle encryption of a small number of disks with negligible performance impact. They also retain performance better as the number of disks increases. Older processors without the AES-NI instructions see significant performance impact with even a single encrypted disk. This forum post compares the performance of various processors.
All drives in an encrypted pool are encrypted, including L2ARC (read cache) and SLOG (write cache). Drives added to an existing encrypted pool are encrypted with the same method specified when the pool was created. Data in memory, including ARC, is not encrypted. ZFS data on disk, including L2ARC and SLOG, are encrypted if the underlying disks are encrypted. Swap data on disk is always encrypted.
Encryption performance depends upon the number of disks encrypted. The more drives in an encrypted pool, the more encryption and decryption overhead, and the greater the impact on performance. Encrypted pools composed of more than eight drives can suffer severe performance penalties. Please benchmark encrypted pools before using them in production.
Creating an encrypted pool means GELI encrypts the data on the disk and generates a master key to decrypt this data. This master key is also encrypted. Loss of a disk master key due to disk corruption is equivalent to any other disk failure, and in a redundant pool, other disks will contain accessible copies of the uncorrupted data. While it is possible to separately back up disk master keys, it is usually not necessary or useful.
There are two user keys that can be used to unlock the master key and then decrypt the disks. In FreeNAS®, these user keys are named the encryption key and the recovery key. Because data cannot be read without first providing a key, encrypted disks containing sensitive data can be safely removed, reused, or discarded without secure wiping or physical destruction of the media.
When discarding disks that still contain encrypted sensitive data, the encryption and recovery keys should also be destroyed or securely deleted. Keys that are not destroyed must be stored securely and kept physically separate from the discarded disks. Data is vulnerable to decryption when the encryption key is present with the discarded disks or can be obtained by the same person who gains access to the disks.
This encryption method is not designed to protect against unauthorized access when the pool is already unlocked. Before sensitive data is stored on the system, ensure that only authorized users have access to the web interface and that permissions with appropriate restrictions are set on shares.
Here are some important points about FreeNAS® behavior to remember when creating or using an encrypted pool:
- At present, there is no one-step way to encrypt an existing pool. The data must be copied to an existing or new encrypted pool. After that, the original pool and any unencrypted backup should be destroyed to prevent unauthorized access and any disks that contained unencrypted data should be wiped.
- Hybrid pools are not supported. Added vdevs must match the existing encryption scheme. Extending a Pool automatically encrypts a new vdev being added to an existing encrypted pool.
- FreeNAS® encryption differs from the encryption used in the Oracle proprietary version of ZFS. To convert between these formats, both pools must be unlocked, and the data copied between them.
- Each pool has a separate encryption key. Pools can also add a unique recovery key to use if the passphrase is forgotten or encryption key invalidated.
- Encryption applies to a pool, not individual users. The data from an unlocked pool is accessible to all users with permissions to access it. Encrypted pools with a passphrase can be locked on demand by users that know the passphrase. Pools are automatically locked when the system is shut down.
- Encrypted data cannot be accessed when the disks are removed or the system has been shut down. On a running system, encrypted data cannot be accessed when the pool is locked.
- Encrypted pools that have no passphrase are unlocked at startup. Pools with a passphrase remain locked until a user enters the passphrase to unlock them.
10.2.2.1. Encryption and Recovery Keys¶
FreeNAS® generates a randomized encryption key whenever a new encrypted pool is created. This key is stored in the system dataset. It is the primary key used to unlock the pool each time the system boots. Creating a passphrase for the pool adds a passphrase component to the encryption key and allows the pool to be locked.
A pool encryption key backup can be downloaded to allow disk decryption on a different system in the event of failure or to allow the FreeNAS® stored key to be deleted for extra security. The combination of encryption key location and passphrase usage provide several different security scenarios:
- Key stored locally, no passphrase: the encrypted pool is decrypted and accessible when the system running. Protects “data at rest” only.
- Key stored locally, with passphrase: the encrypted pool is not accessible until the passphrase is entered by the FreeNAS® administrator.
- Key not stored locally: the encrypted pool is not accessible until the FreeNAS® administrator uploads the key file. When the key also has a passphrase, it must be provided with the key file.
Encrypted pools cannot be locked in the web interface until a passphrase is created for the encryption key.
The recovery key is an optional keyfile that is generated by FreeNAS®, provided for download, and wiped from the system. It is designed as an emergency backup to unlock or import an encrypted pool if the passphrase is forgotten or the encryption key is somehow invalidated. This file is not stored anywhere on the FreeNAS® system and only one recovery key can exist for each encrypted pool. Adding a new recovery key invalidates any previously downloaded recovery key file for that pool.
Existing encryption or recovery keys can be invalidated in several situations:
- An encryption re-key invalidates all encryption and recovery keys as well as an existing passphrase.
- Using a recovery key file to import an encrypted pool invalidates the existing encryption key and passphrase for that pool. FreeNAS® generates a new encryption key for the imported pool, but a new passphrase must be created before the pool can be locked.
- Creating or changing a passphrase invalidates any existing recovery key.
- Adding a new recovery key invalidates any existing recovery key files for the pool.
- Extending a Pool invalidates all encryption and recovery keys as well as an existing passphrase.
Be sure to download and securely store copies of the most current encryption and recovery keys. Protect and backup encryption key passphrases. Losing the encryption and recovery keys or the passphrase can result in irrevocably losing all access to the data stored in the encrypted pool!
10.2.2.2. Encryption Operations¶
Encryption operations are seen by clicking (Encryption Options) for the encrypted pool in . These options are available:
Lock: Only appears after a passphrase is created. Locking a pool restricts data accessability in FreeNAS® until the pool is unlocked. Selecting this action requires entering the passphrase. The pool status changes to
LOCKED, Pool Operations are limited to Export/Disconnect, and (Encryption Options) changes to (Unlock).Unlock: Decrypt the pool by clicking (Unlock) and entering the passphrase or uploading the recovery key file. Only the passphrase is used when both a passphrase and a recovery key are entered. The services listed in Restart Services restart when the pool is unlocked. This enables FreeNAS® to begin accessing the decrypted data. Individual services can be prevented from restarting by opening Restart Services and deselecting them. Deselecting services can prevent them from properly accessing the unlocked pool.
Encryption Key/Passphrase: Create or change the encryption key passphrase and download a backup of the encryption key. Unlike a password, a passphrase can contain spaces and is typically a series of words. A good passphrase is easy to remember but hard to guess.
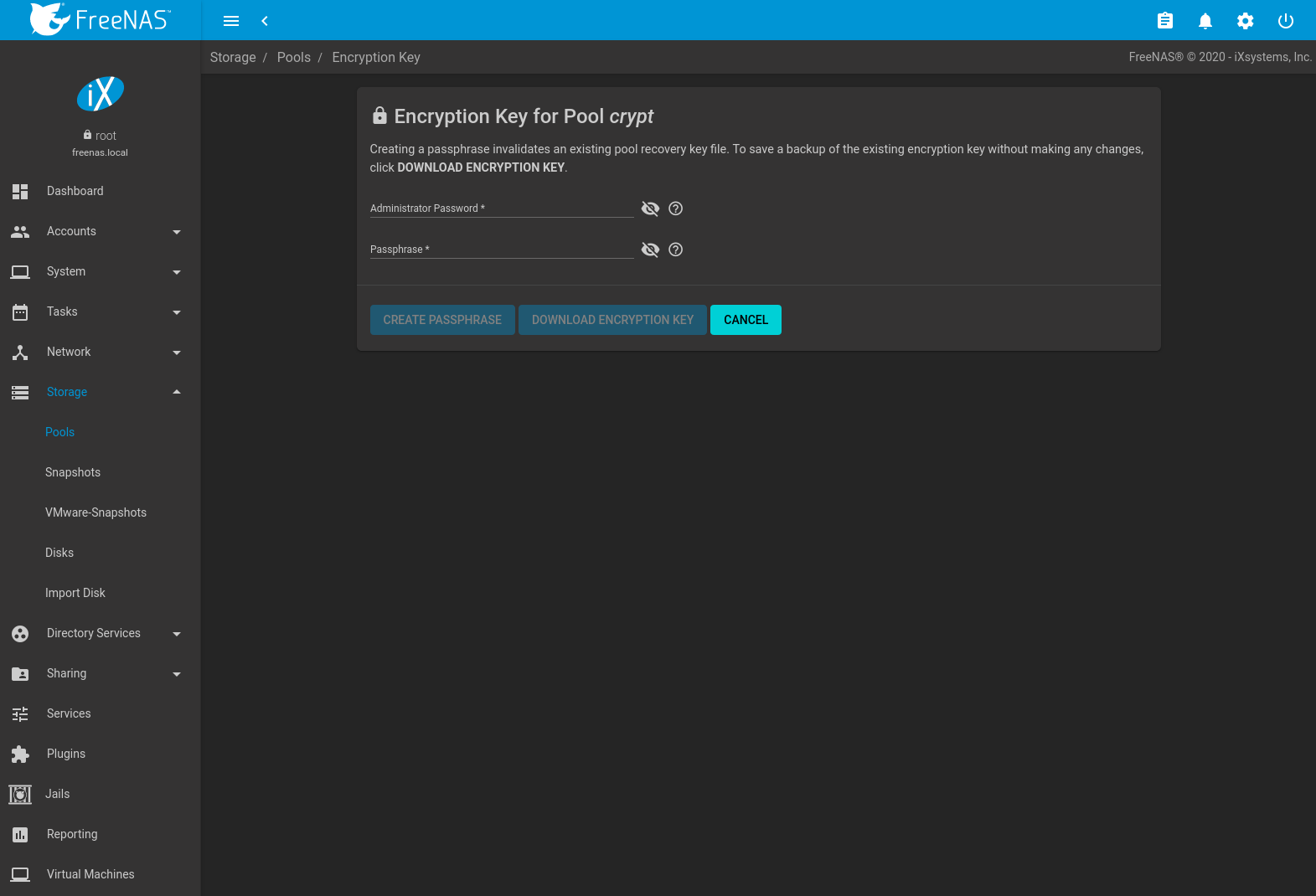
Fig. 10.2.3 Encryption Key/Passphrase Options
The administrator password is required for encryption key changes. Setting Remove Passphrase invalidates the current pool passphrase. Creating or changing a passphrase invalidates the pool recovery key.
Recovery Key: Generate and download a new recovery key file or invalidate an existing recovery key. The FreeNAS® administrative password is required. Generating a new recovery key file invalidates previously downloaded recovery key files for the pool.
Reset Keys: Reset the encryption on the pool GELI master key and invalidate all encryption keys, recovery keys, and any passphrase for the pool. A dialog opens to save a backup of the new encryption key. A new passphrase can be created and a new pool recovery key file can be downloaded. The administrator password is required to reset pool encryption.
If a key reset fails on a multi-disk system, an alert is generated. Do not ignore this alert as doing so may result in the loss of data.
10.2.3. Adding Cache or Log Devices¶
Pools can be used either during or after pool creation to add an SSD as a cache or log device to improve performance of the pool under specific use cases. Before adding a cache or log device, refer to the ZFS Primer to determine if the system will benefit or suffer from the addition of the device.
To add a Cache or Log device during pool creation, click the Add Cache or Add Log button. Select the disk from Available Disks and use the right arrow next to Cache VDev or Log VDev to add it to that section.
To add a device to an existing pool, Extend that pool.
10.2.4. Removing Cache or Log Devices¶
Cache or log devices can be removed by going to . Choose the desired pool and click (Settings) . Choose the log or cache device to remove, then click (Options) .
10.2.5. Adding Spare Devices¶
ZFS provides the ability to have “hot” spares. These are drives that are connected to a pool, but not in use. If the pool experiences the failure of a data drive, the system uses the hot spare as a temporary replacement. If the failed drive is replaced with a new drive, the hot spare drive is no longer needed and reverts to being a hot spare. If the failed drive is detached from the pool, the spare is promoted to a full member of the pool.
Hot spares can be added to a pool during or after creation. On FreeNAS®, hot spare actions are implemented by zfsd(8).
To add a spare during pool creation, click the Add Spare. button. Select the disk from Available Disks and use the right arrow next to Spare VDev to add it to the section.
To add a device to an existing pool, Extend that pool.
10.2.6. Extending a Pool¶
To increase the capacity of an existing pool, click the pool name, (Settings), then .
If the existing pool is encrypted, an additional warning message shows a reminder that extending a pool resets the passphrase and recovery key. Extending an encrypted pool opens a dialog to download the new encryption key file. Remember to use the Encryption Operations to set a new passphrase and create a new recovery key file.
When adding disks to increase the capacity of a pool, ZFS supports the addition of virtual devices, or vdevs, to an existing ZFS pool. After a vdev is created, more drives cannot be added to that vdev, but a new vdev can be striped with another of the same type to increase the overall size of the pool. To extend a pool, the vdev being added must be the same type as existing vdevs. The EXTEND button is only enabled when the vdev being added is the same type as the existing vdevs. Some vdev extending examples:
- to extend a ZFS mirror, add the same number of drives. The result is a striped mirror. For example, if ten new drives are available, a mirror of two drives could be created initially, then extended by adding another mirror of two drives, and repeating three more times until all ten drives have been added.
- to extend a three-drive RAIDZ1, add another three drives. The resulting pool is a stripe of two RAIDZ1 vdevs, similar to RAID 50 on a hardware controller.
- to extend a four-drive RAIDZ2, add another four drives. The result is a stripe of RAIDZ2 vdevs, similar to RAID 60 on a hardware controller.
10.2.7. Export/Disconnect a Pool¶
Export/Disconnect is used to cleanly disconnect a pool from the system. This is used before physically disconnecting the pool so it can be imported on another system, or to optionally detach and erase the pool so the disks can be reused.
To export or destroy an existing pool, click the pool name, (Settings), then Export/Disconnect. A dialog shows which system Services will be disrupted by exporting the pool and additional warnings for encrypted pools. Keep or erase the contents of the pool by setting the options shown in Figure 10.2.4.
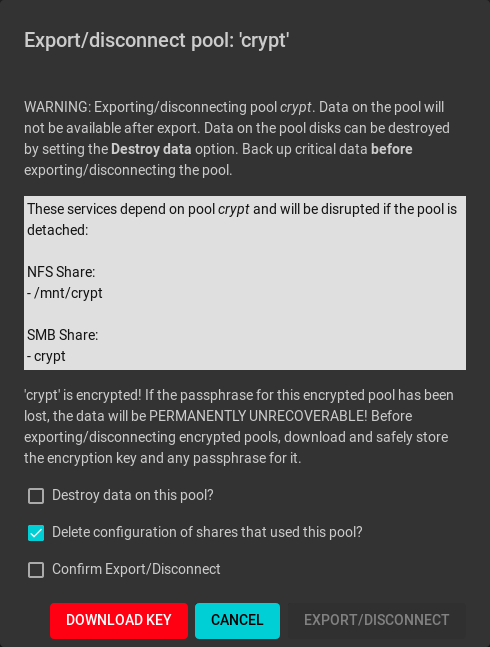
Fig. 10.2.4 Export/Disconnect a Pool
Warning
Do not export/disconnect an encrypted pool if the passphrase has not been set! An encrypted pool cannot be reimported without a passphrase! When in doubt, use the instructions in Managing Encrypted Pools to set a passphrase.
The Export/Disconnect Pool screen provides these options:
| Setting | Description |
|---|---|
| Destroy data on this pool? | Destroy all data on the disks in the pool. This action cannot be undone. |
| Delete configuration of shares | Delete any share configurations set up on the pool. |
| Confirm export/disconnect | Confirm the export/disconnect operation. |
If the pool is encrypted, DOWNLOAD KEY is also shown to download the encryption key for that pool.
To Export/Disconnect the pool and keep the data and configurations of shares, set only Confirm export/disconnect and click EXPORT/DISCONNECT.
To instead destroy the data and share configurations on the pool, also set the Destroy data on this pool? option. To verify that data on the pool is to be destroyed, type the name of the pool and click EXPORT/DISCONNECT. Data on the pool is destroyed, including share configuration, zvols, datasets, and the pool itself. The disk is returned to a raw state.
Danger
Before destroying a pool, ensure that any needed data has been backed up to a different pool or system.
10.2.8. Importing a Pool¶
A pool that has been exported and disconnected from the system can be reconnected with , then selecting Import an existing pool. This works for pools that were exported/disconnected from the current system, created on another system, or to reconnect a pool after reinstalling the FreeNAS® system.
When physically installing ZFS pool disks from another system, use the
zpool export poolname command or a web interface equivalent to
export the pool on that system. Then shut it down and connect the drives
to the FreeNAS® system. This prevents an “in use by another machine”
error during the import to FreeNAS®.
Existing ZFS pools can be imported by clicking and ADD. Select Import an existing pool, then click NEXT as shown in Figure 10.2.5.
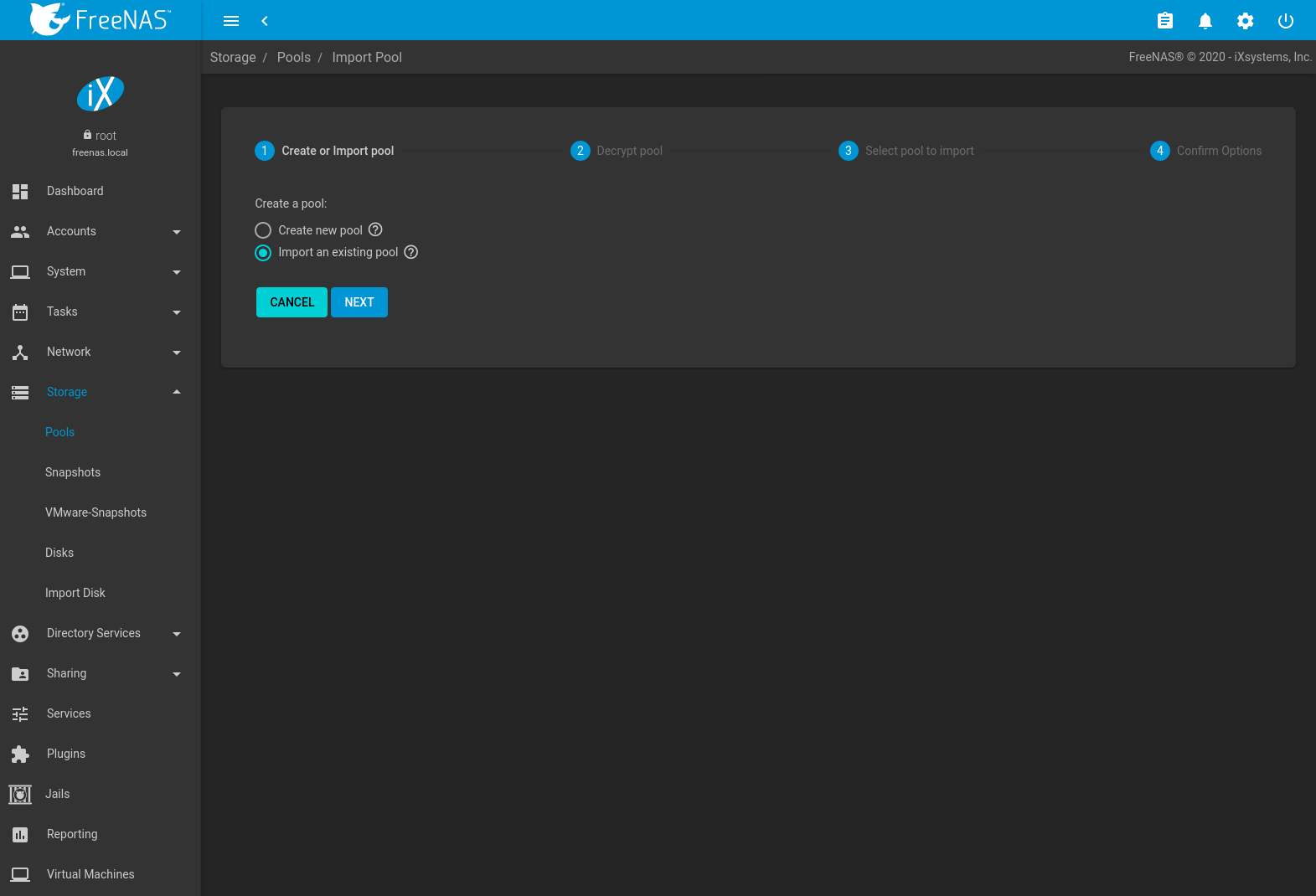
Fig. 10.2.5 Pool Import
To import a pool, click No, continue with import then NEXT as shown in Figure 10.2.6.
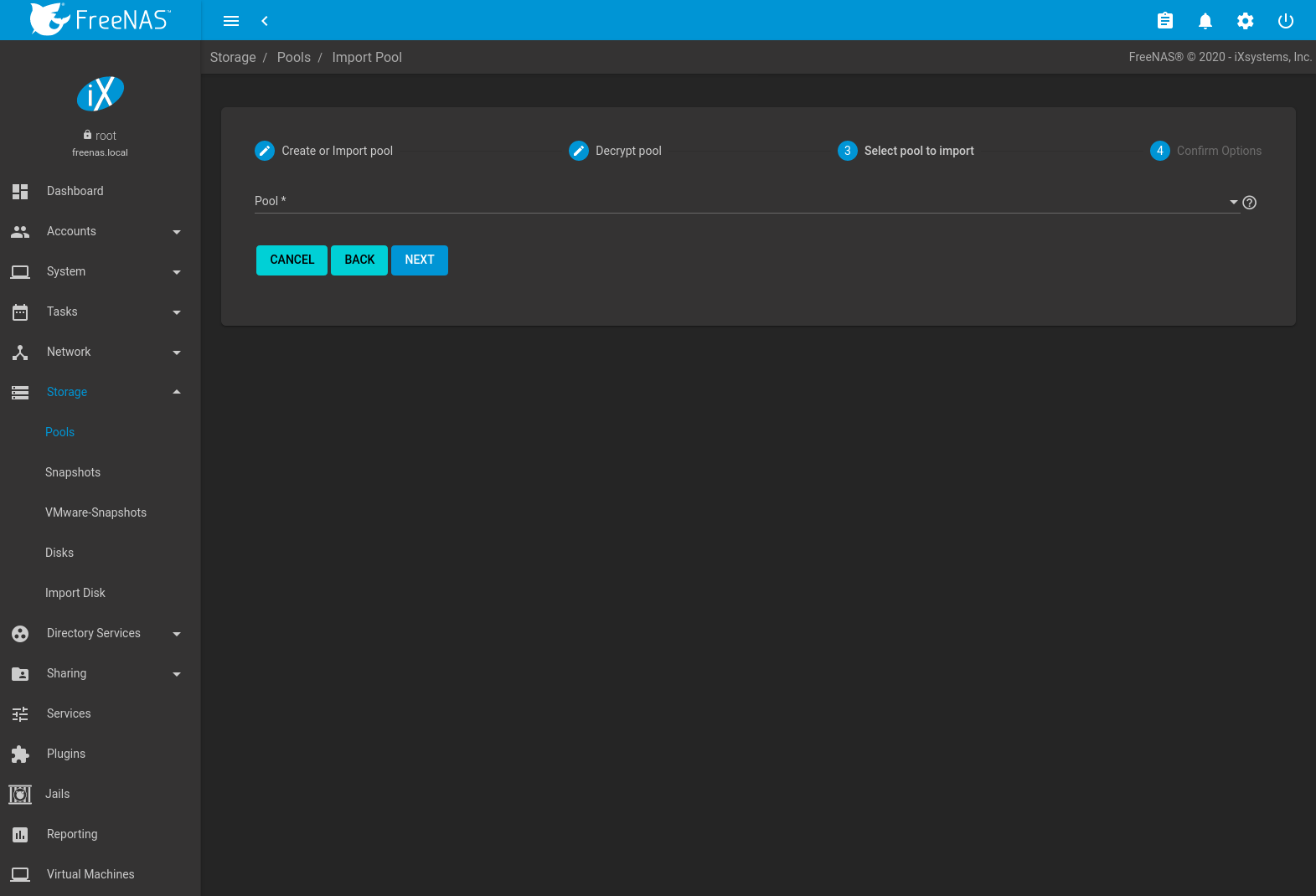
Fig. 10.2.6 Importing a Pool
Select the pool from the Pool * drop-down menu and click NEXT to confirm the options and IMPORT it.
If hardware is not being detected, run camcontrol devlist from Shell. If the disk does not appear in the output, check to see if the controller driver is supported or if it needs to be loaded using Tunables.
Before importing an encrypted pool, disks must first be decrypted. Click Yes, decrypt the disks. This is shown in Figure 10.2.7.
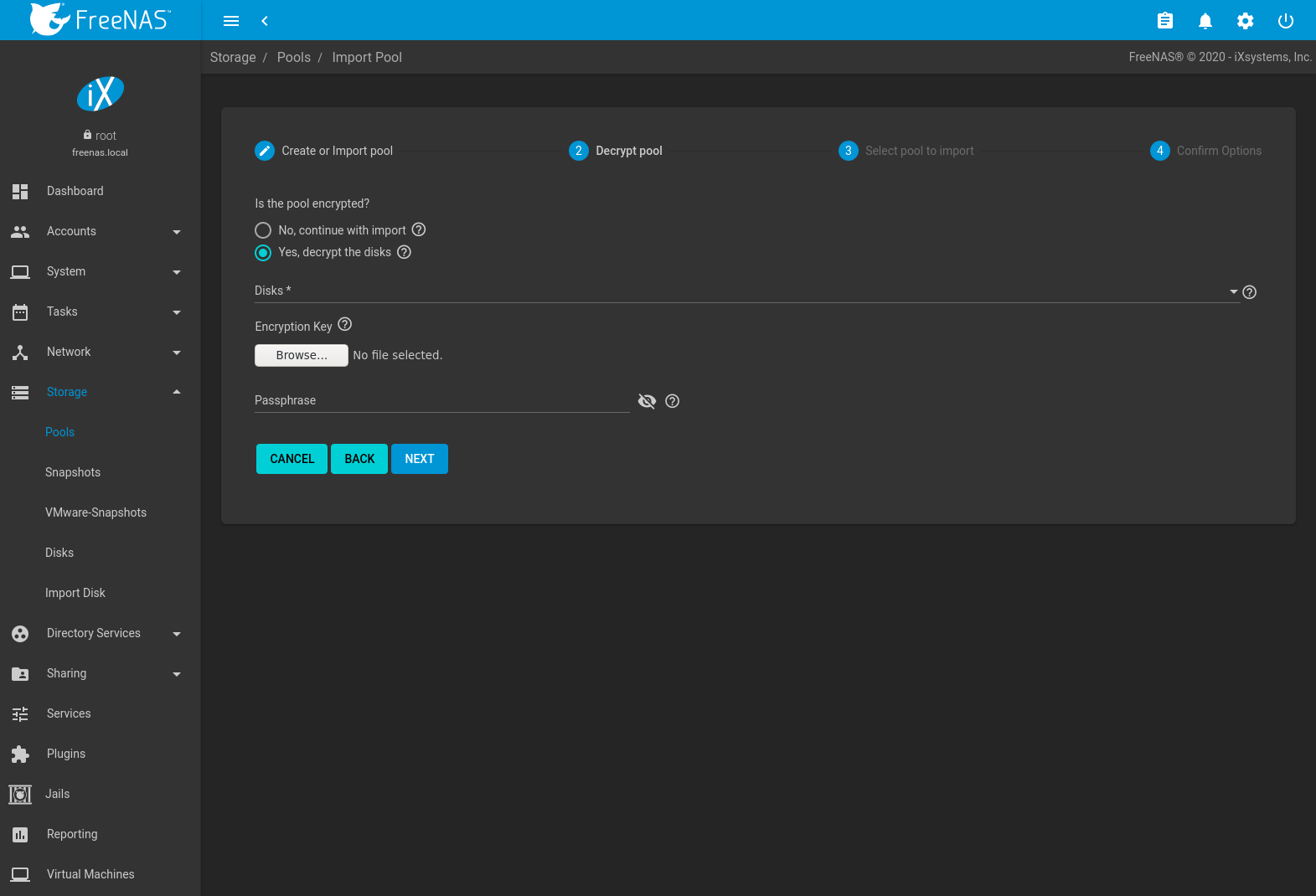
Fig. 10.2.7 Decrypting Disks Before Importing a Pool
Use the Disks dropdown menu to select the disks to decrypt. Click Browse to select the encryption key file stored on the client system. Enter the Passphrase associated with the encryption key, then click NEXT to continue importing the pool.
Danger
The encryption key file and passphrase are required to decrypt the pool. If the pool cannot be decrypted, it cannot be re-imported after a failed upgrade or lost configuration. This means it is very important to save a copy of the key and to remember the passphrase that was configured for the key. Refer to Managing Encrypted Pools for instructions on managing keys.
Select the pool to import and confirm the settings. Click IMPORT to finish the process.
Note
For security reasons, encrypted pool keys are not saved in a configuration backup file. When FreeNAS® has been installed to a new device and a saved configuration file restored to it, the keys for encrypted disks will not be present, and the system will not request them. To correct this, export the encrypted pool with (Configure) , making sure that Destroy data on this pool? is not set. Then import the pool again. During the import, the encryption keys can be entered as described above.
10.2.9. Viewing Pool Scrub Status¶
Scrubs and how to set their schedule are described in more detail in Scrub Tasks.
To view the scrub status of a pool, click the pool name, (Settings), then Status. The resulting screen will display the status and estimated time remaining for a running scrub or the statistics from the last completed scrub.
A CANCEL button is provided to cancel a scrub in progress. When a scrub is cancelled, it is abandoned. The next scrub to run starts from the beginning, not where the cancelled scrub left off.
10.2.10. Adding Datasets¶
An existing pool can be divided into datasets. Permissions, compression, deduplication, and quotas can be set on a per-dataset basis, allowing more granular control over access to storage data. Like a folder or directory, permissions can be set on dataset. Datasets are also similar to filesystems in that properties such as quotas and compression can be set, and snapshots created.
Note
ZFS provides thick provisioning using quotas and thin provisioning using reserved space.
To create a dataset, select an existing pool in , click (Options), then select Add Dataset This will display the screen shown in Figure 10.2.8.
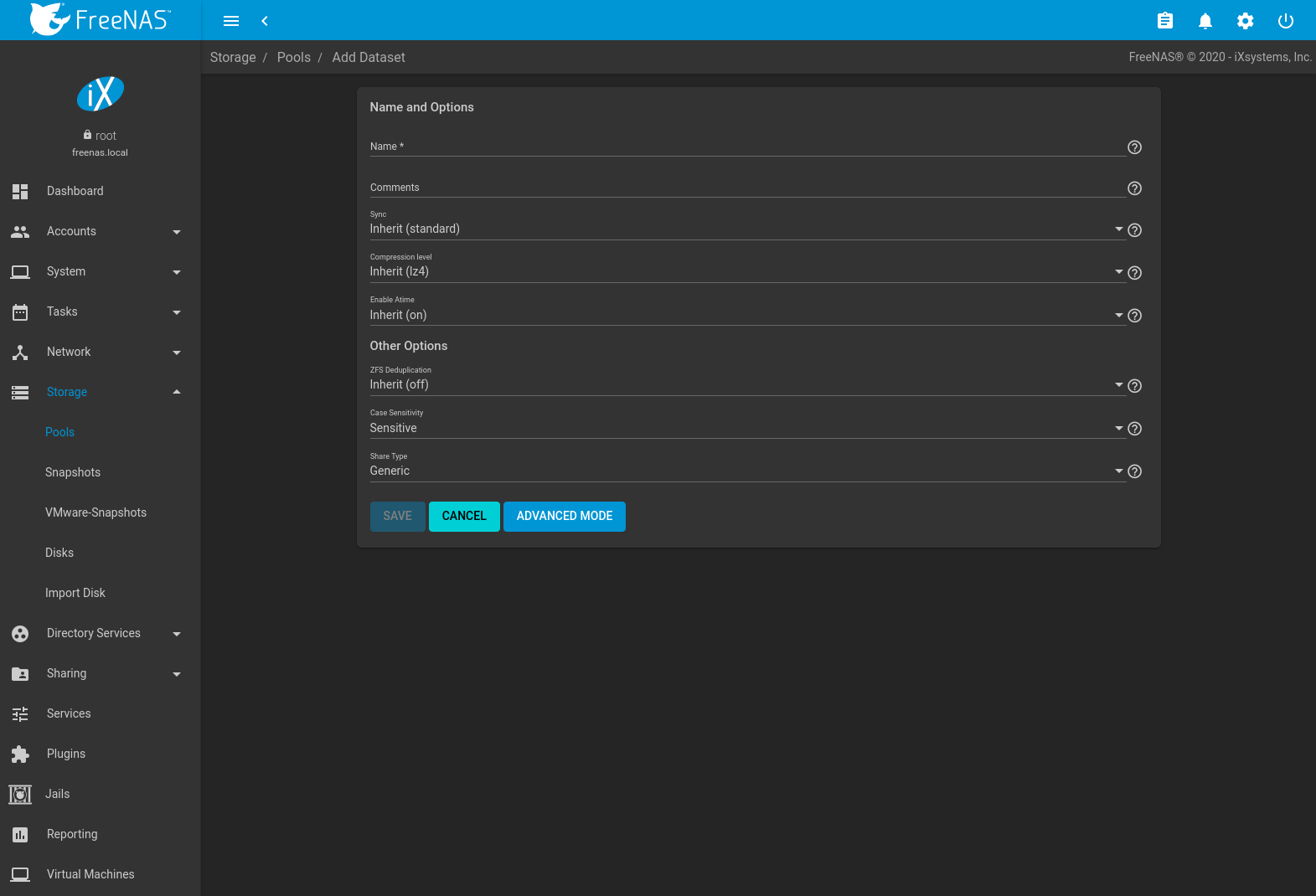
Fig. 10.2.8 Creating a ZFS Dataset
Table 10.2.3 shows the options available when creating a dataset.
Some settings are only available in ADVANCED MODE. To see these settings, either click the ADVANCED MODE button, or configure the system to always display advanced settings by enabling the Show advanced fields by default option in .
| Setting | Value | Advanced Mode | Description |
|---|---|---|---|
| Name | string | Required. Enter a unique name for the dataset. | |
| Comments | string | Enter any additional comments or user notes about this dataset. | |
| Sync | drop-down menu | Set the data write synchronization. Inherit inherits the sync settings from the parent dataset, Standard uses the sync settings that have been requested by the client software, Always waits for data writes to complete, and Disabled never waits for writes to complete. | |
| Compression Level | drop-down menu | Refer to the section on Compression for a description of the available algorithms. | |
| Enable atime | Inherit, On, or Off | Choose On to update the access time for files when they are read. Choose Off to prevent producing log traffic when reading files. This can result in significant performance gains. | |
| Quota for this dataset | integer | ✓ | Default of 0 disables quotas. Specifying a value means to use no more than the specified size and is suitable for user datasets to prevent users from hogging available space. |
| Quota warning alert at, % | integer | ✓ | Set Inherit to apply the same quota warning alert settings as the parent dataset. |
| Quota critical alert at, % | integer | ✓ | Set Inherit to apply the same quota critical alert settings as the parent dataset. |
| Quota for this dataset and all children | integer | ✓ | A specified value applies to both this dataset and any child datasets. |
| Quota warning alert at, % | integer | ✓ | Set Inherit to apply the same quota warning alert settings as the parent dataset. |
| Quota critical alert at, % | integer | ✓ | Set Inherit to apply the same quota critical alert settings as the parent dataset. |
| Reserved space for this dataset | integer | ✓ | Default of 0 is unlimited. Specifying a value means to keep at least this much space free and is suitable for datasets containing logs which could otherwise take up all available free space. |
| Reserved space for this dataset and all children | integer | ✓ | A specified value applies to both this dataset and any child datasets. |
| ZFS Deduplication | drop-down menu | Read the section on Deduplication before making a change to this setting. | |
| Read-only | drop-down menu | ✓ | Choices are Inherit, On, or Off. |
| Exec | drop-down menu | ✓ | Choices are Inherit, On, or Off. Setting to Off prevents the installation of Plugins or Jails. |
| Snapshot directory | drop-down menu | ✓ | Choose if the .zfs snapshot directory is Visible or Invisible on this dataset. |
| Copies | drop-down menu | ✓ | Set the number of data copies on this dataset. |
| Record Size | drop-down menu | ✓ | While ZFS automatically adapts the record size dynamically to adapt to data, if the data has a fixed size (such as database records), matching its size might result in better performance. Warning: choosing a smaller record size than the suggested value can reduce disk performance and space efficiency. |
| ACL Mode | drop-down menu | ✓ | Determine how chmod(2) behaves when adjusting file ACLs. See the zfs(8) aclmode property. Passthrough only updates ACL entries that are related to the file or directory mode. Restricted does not allow chmod to make changes to files or directories with a non-trivial
ACL. An ACL is trivial if it can be fully expressed as a file mode without losing any access rules.
Setting the ACL Mode to Restricted is typically used to optimize a dataset for
SMB sharing, but can require further optimizations. For example,
configuring an rsync with this dataset could require adding |
| Case Sensitivity | drop-down menu | Choices are sensitive (default, assumes filenames are case sensitive), insensitive (assumes filenames are not case sensitive), or mixed (understands both types of filenames). This can only be set when creating a new dataset. | |
| Share Type | drop-down menu | Select the type of share that will be used on the dataset. Choose between Generic for most sharing options or SMB for a SMB share. Choosing SMB sets the ACL Mode to Restricted and Case Sensitivity to Insensitive. This field is only available when creating a new dataset. |
After a dataset is created it appears in . Click (Options) on an existing dataset to configure these options:
Add Dataset: create a nested dataset, or a dataset within a dataset.
Add Zvol: add a zvol to the dataset. Refer to Adding Zvols for more information about zvols.
Edit Options: edit the pool properties described in Table 10.2.8. Note that Dataset Name and Case Sensitivity are read-only as they cannot be edited after dataset creation.
Edit Permissions: refer to Setting Permissions for more information about permissions.
Danger
Removing a dataset is a permanent action and results in data loss!
Edit ACL: see ACL Management for details about modifying an Access Control List (ACL).
Delete Dataset: removes the dataset, snapshots of that dataset, and any objects stored within the dataset. To remove the dataset, set Confirm, click DELETE DATASET, verify that the correct dataset to be deleted has been chosen by entering the dataset name, and click DELETE. When the dataset has active shares or is still being used by other parts of the system, the dialog shows what is still using it and allows forcing the deletion anyway. Caution: forcing the deletion of an in-use dataset can cause data loss or other problems.
Promote Dataset: only appears on clones. When a clone is promoted, the origin filesystem becomes a clone of the clone making it possible to destroy the filesystem that the clone was created from. Otherwise, a clone cannot be deleted while the origin filesystem exists.
Create Snapshot: create a one-time snapshot. A dialog opens to name the snapshot. Options to include child datasets in the snapshot and synchronize with VMware can also be shown. To schedule snapshot creation, use Periodic Snapshot Tasks.
10.2.10.1. Deduplication¶
Deduplication is the process of ZFS transparently reusing a single copy of duplicated data to save space. Depending on the amount of duplicate data, deduplicaton can improve storage capacity, as less data is written and stored. However, deduplication is RAM intensive. A general rule of thumb is 5 GiB of RAM per terabyte of deduplicated storage. In most cases, compression provides storage gains comparable to deduplication with less impact on performance.
In FreeNAS®, deduplication can be enabled during dataset creation. Be forewarned that there is no way to undedup the data within a dataset once deduplication is enabled, as disabling deduplication has NO EFFECT on existing data. The more data written to a deduplicated dataset, the more RAM it requires. When the system starts storing the DDTs (dedup tables) on disk because they no longer fit into RAM, performance craters. Further, importing an unclean pool can require between 3-5 GiB of RAM per terabyte of deduped data, and if the system does not have the needed RAM, it will panic. The only solution is to add more RAM or recreate the pool. Think carefully before enabling dedup! This article provides a good description of the value versus cost considerations for deduplication.
Unless a lot of RAM and a lot of duplicate data is available, do not change the default deduplication setting of “Off”. For performance reasons, consider using compression rather than turning this option on.
If deduplication is changed to On, duplicate data blocks are removed synchronously. The result is that only unique data is stored and common components are shared among files. If deduplication is changed to Verify, ZFS will do a byte-to-byte comparison when two blocks have the same signature to make sure that the block contents are identical. Since hash collisions are extremely rare, Verify is usually not worth the performance hit.
Note
After deduplication is enabled, the only way to disable it
is to use the zfs set dedup=off dataset_name command
from Shell. However, any data that has already been
deduplicated will not be un-deduplicated. Only newly stored data
after the property change will not be deduplicated. The only way to
remove existing deduplicated data is to copy all of the data off of
the dataset, set the property to off, then copy the data back in
again. Alternately, create a new dataset with
ZFS Deduplication left at Off, copy the data to the
new dataset, and destroy the original dataset.
Tip
Deduplication is often considered when using a group of very similar virtual machine images. However, other features of ZFS can provide dedup-like functionality more efficiently. For example, create a dataset for a standard VM, then clone a snapshot of that dataset for other VMs. Only the difference between each created VM and the main dataset are saved, giving the effect of deduplication without the overhead.
10.2.10.2. Compression¶
When selecting a compression type, balancing performance with the amount of disk space saved by compression is recommended. Compression is transparent to the client and applications as ZFS automatically compresses data as it is written to a compressed dataset or zvol and automatically decompresses that data as it is read. These compression algorithms are supported:
- LZ4: default and recommended compression method as it allows compressed datasets to operate at near real-time speed. This algorithm only compresses files that will benefit from compression.
- GZIP: levels 1, 6, and 9 where gzip fastest (level 1) gives the least compression and gzip maximum (level 9) provides the best compression but is discouraged due to its performance impact.
- ZLE: fast but simple algorithm which eliminates runs of zeroes.
If OFF is selected as the Compression level when creating a dataset or zvol, compression will not be used on that dataset/zvol. This is not recommended as using LZ4 has a negligible performance impact and allows for more storage capacity.
10.2.11. Adding Zvols¶
A zvol is a feature of ZFS that creates a raw block device over ZFS. The zvol can be used as an iSCSI device extent.
To create a zvol, select an existing ZFS pool or dataset, click (Options), then Add Zvol to open the screen shown in Figure 10.2.9.
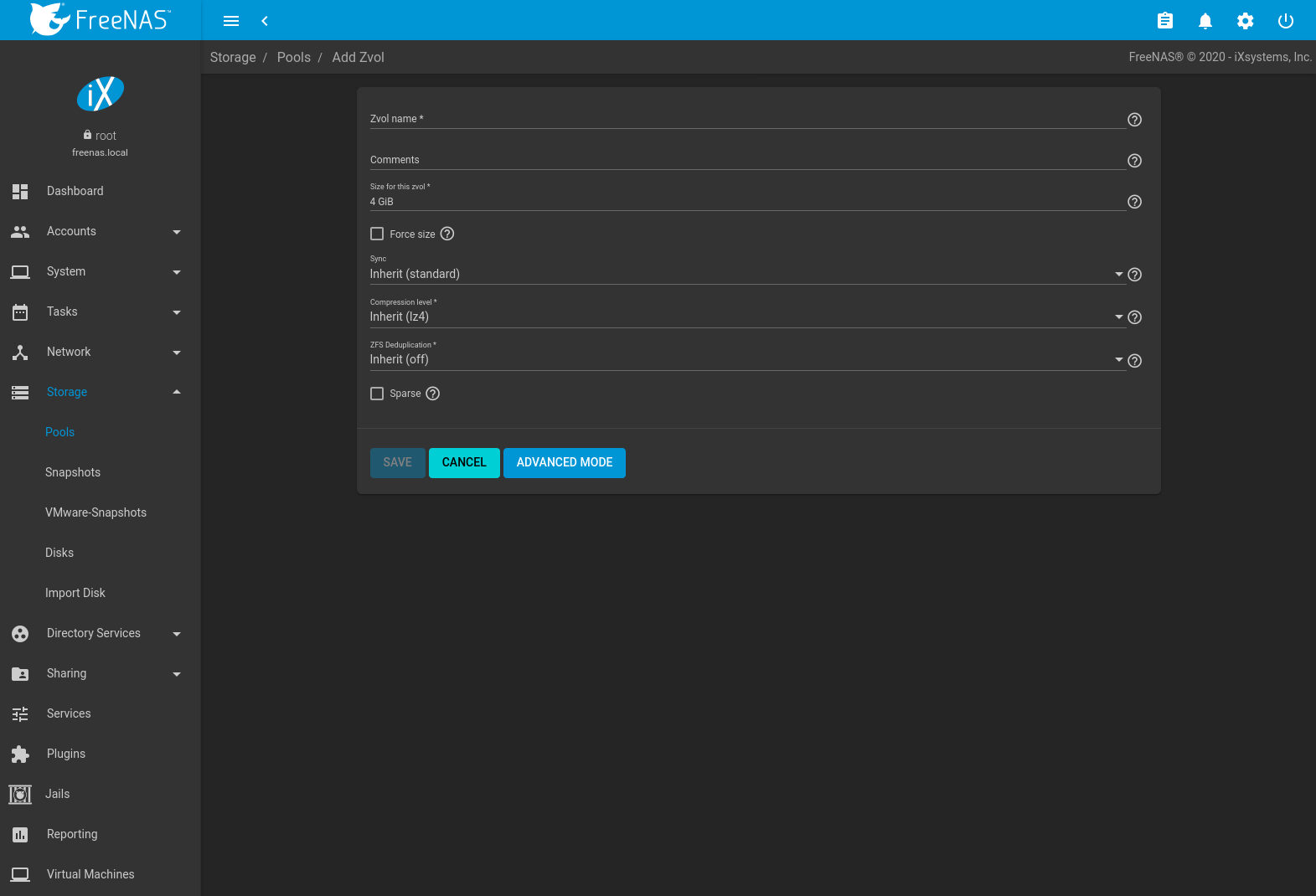
Fig. 10.2.9 Adding a Zvol
The configuration options are described in Table 10.2.4.
| Setting | Value | Advanced Mode | Description |
|---|---|---|---|
| zvol name | string | Enter a short name for the zvol. Using a zvol name longer than 63-characters can prevent accessing zvols as devices. For example, a zvol with a 70-character filename or path cannot be used as an iSCSI extent. This setting is mandatory. | |
| Comments | string | Enter any notes about this zvol. | |
| Size for this zvol | integer | Specify size and value. Units like t, TiB, and G can be used. The size of the
zvol can be increased later, but cannot be reduced. If the size is more than 80% of the available capacity,
the creation will fail with an “out of space” error unless Force size is also enabled. |
|
| Force size | checkbox | By default, the system will not create a zvol if that operation will bring the pool to over 80% capacity. While NOT recommended, enabling this option will force the creation of the zvol. | |
| Sync | drop-down menu | Sets the data write synchronization. Inherit inherits the sync settings from the parent dataset, Standard uses the sync settings that have been requested by the client software, Always waits for data writes to complete, and Disabled never waits for writes to complete. | |
| Compression level | drop-down menu | Compress data to save space. Refer to Compression for a description of the available algorithms. | |
| ZFS Deduplication | drop-down menu | ZFS feature to transparently reuse a single copy of duplicated data to save space. Warning: this option is RAM intensive. Read the section on Deduplication before making a change to this setting. | |
| Sparse | checkbox | Used to provide thin provisioning. Use with caution as writes will fail when the pool is low on space. | |
| Block size | drop-down menu | ✓ | The default is based on the number of disks in the pool. This can be set to match the block size of the filesystem which will be formatted onto the iSCSI target. Warning: Choosing a smaller record size than the suggested value can reduce disk performance and space efficiency. |
Click (Options) next to the desired zvol in to access the Delete zvol, Edit Zvol, Create Snapshot, and, for an existing zvol snapshot, Promote Dataset options.
Similar to datasets, a zvol name cannot be changed.
Choosing a zvol for deletion shows a warning that all snapshots of that zvol will also be deleted.
10.2.12. Setting Permissions¶
Setting permissions is an important aspect of managing data access. The web interface is meant to set the initial permissions for a pool or dataset to make it available as a share. When a share is made available, the client operating system and ACL manager is used to fine-tune the permissions of the files and directories that are created by the client.
Sharing contains configuration examples for several types of permission scenarios. This section provides an overview of the options available for configuring the initial set of permissions.
Note
For users and groups to be available, they must either be first created using the instructions in Accounts or imported from a directory service using the instructions in Directory Services. The drop-down menus described in this section are automatically truncated to 50 entries for performance reasons. To find an unlisted entry, begin typing the desired user or group name for the drop-down menu to show matching results.
To set the permissions on a dataset, select it in , click (Options), then Edit Permissions. Table 10.2.5 describes the options in this screen.
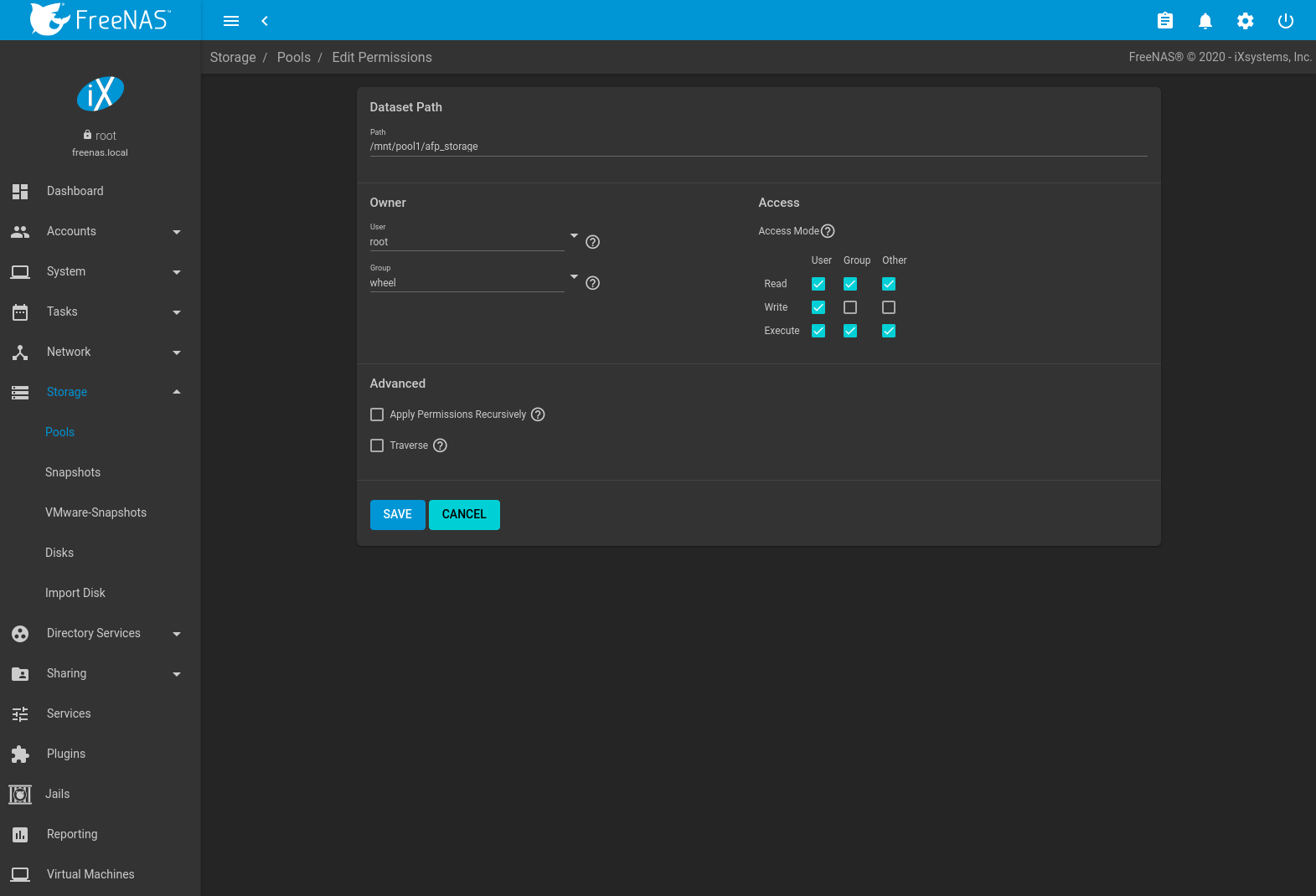
Fig. 10.2.10 Editing Dataset Permissions
| Setting | Value | Description |
|---|---|---|
| Path | string | Displays the path to the dataset or zvol directory. |
| User | drop-down menu | Select the user to control the dataset. Users created manually or imported from a directory service appear in the drop-down menu. |
| Group | drop-down menu | Select the group to control the dataset. Groups created manually or imported from a directory service appear in the drop-down menu. |
| Access Mode | checkboxes | Set the read, write, and execute permissions for the dataset. |
| Apply Permissions Recursively | checkbox | Apply permissions recursively to all directories and files within the current dataset. |
| Traverse | checkbox | Movement permission for this dataset. Allows users to view or interact with child datasets even when those users do not have permission to view or manage the contents of this dataset. |
10.2.13. ACL Management¶
An Access Control List (ACL) is a set of account permissions associated
with a dataset and applied to directories or files within that dataset.
These permissions control the actions users can perform on the dataset
contents. ACLs are typically used to manage user interactions with
shared datasets. Datasets with an ACL have
(ACL) appended to their name in the directory browser.
The ACL for a new file or directory is typically determined by the
parent directory ACL. An exception is when there are no File Inherit
or Directory Inherit flags in the parent
ACL owner@, group@, or everyone@
entries. These non-inheriting entries are appended to the ACL of the
newly created file or directory based on the
Samba create and directory masks
or the
umask
value.
By default, a file ACL is preserved when it is moved or renamed within the same dataset. The SMB winmsa module can override this behavior to force an ACL to be recalculated whenever the file moves, even within the same dataset.
Datasets optimized for SMB sharing can restrict ACL changes. See ACL Mode in the Dataset Options table.
ACLs are modified by adding or removing Access Control Entries (ACEs) in . Find the desired dataset, click (Options), and select Edit ACL. The ACL Manager opens. The ACL manager must be used to modify permissions on a dataset with an ACL.
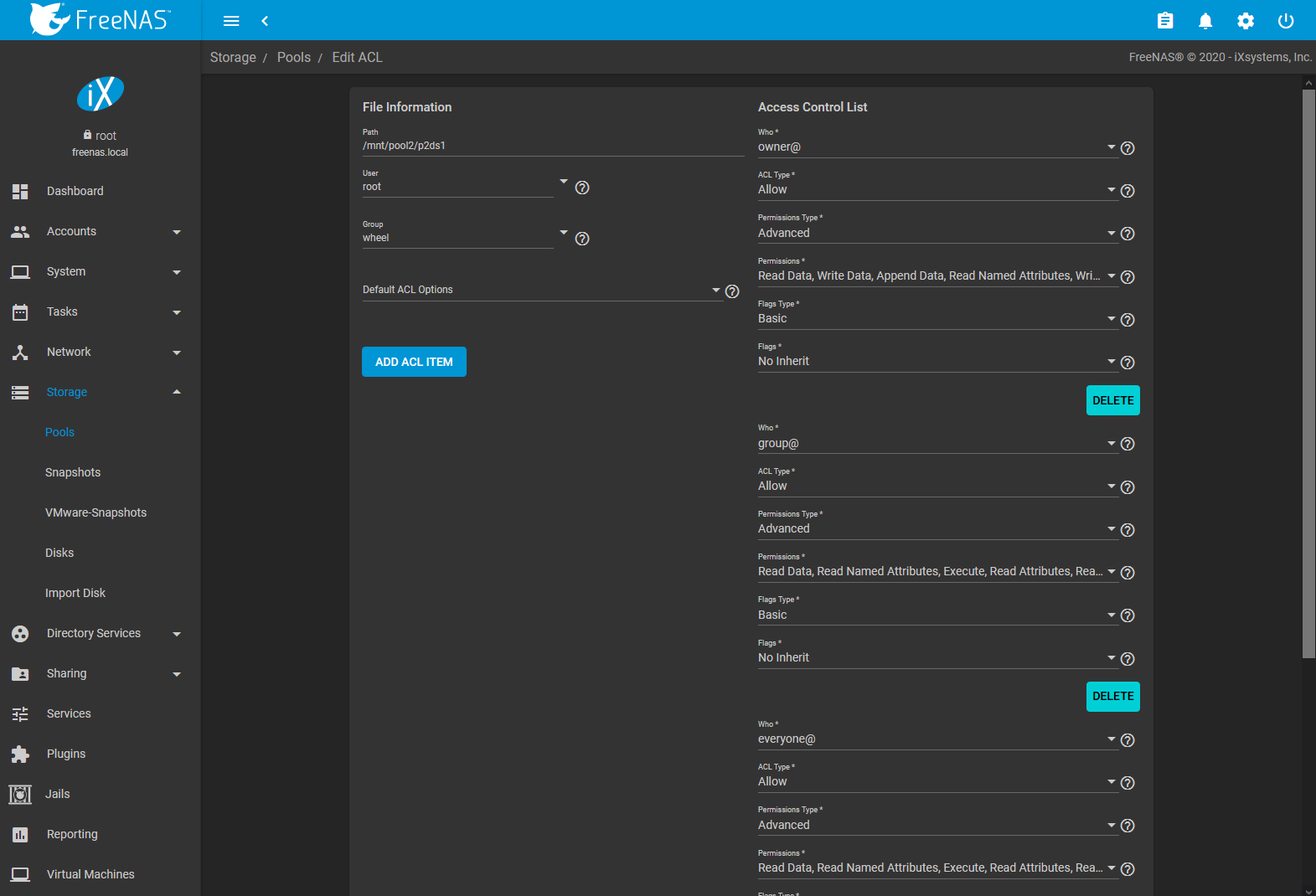
Fig. 10.2.11 ACL Manager
The ACL Manager options are split into the File Information, Access Control List, and Advanced sections. Table 10.2.6 sorts these options by their section.
| Setting | Section | Value | Description |
|---|---|---|---|
| Path | File Information | string | Location of the dataset that is being modified. Read-only. |
| User | File Information | drop-down menu | User who controls the dataset. This user always has permissions to read or write the ACL and read or write attributes. Users created manually or imported from a directory service appear in the drop-down menu. |
| Apply User | File Information | checkbox | Confirm changes to User. To prevent errors, changes to the User are submitted only when this box is set. |
| Group | File Information | drop-down menu | The group which controls the dataset. This group has all permissions that are granted to the @group Tag. Groups created manually or imported from a directory service appear in the drop-down menu. |
| Apply Group | File Information | checkbox | Confirm changes to Group. To prevent errors, changes to the Group are submitted only when this box is set. | |
| Default ACL Options | File Information | drop-down menu | Default ACLs. Choosing an entry loads a preset ACL that is configured to match general permissions situations. |
| Who | Access Control List | drop-down menu | Access Control Entry (ACE) user or group. Select a specific User or Group for this entry, owner@ to apply this entry to the selected User, group@ to apply this entry to the selected Group, or everyone@ to apply this entry to all users and groups. See setfacl(1) NFSv4 ACL ENTRIES. |
| User | Access Control List | drop-down menu | User account to which this ACL entry applies. Only visible when User is the chosen Tag. |
| Group | Access Control List | drop-down menu | Group to which this ACL entry applies. Only visible when Group is the chosen Tag. |
| ACL Type | Access Control List | drop-down menu | How the Permissions are applied to the chosen Who. Choose Allow to grant the specified permissions and Deny to restrict the specified permissions. |
| Permissions Type | Access Control List | drop-down menu | Choose the type of permissions. Basic shows general permissions. Advanced shows each specific type of permission for finer control. |
| Permissions | Access Control List | drop-down menu | Select permissions to apply to the chosen Tag. Choices change depending on the Permissions Type. See the permissions list for descriptions of each permission. |
| Flags Type | Access Control List | drop-down menu | Select the set of ACE inheritance Flags to display. Basic shows unspecific inheritance options. Advanced shows specific inheritance settings for finer control. |
| Flags | Access Control List | drop-down menu | How this ACE is applied to newly created directories and files within the dataset. Basic flags enable or disable ACE inheritance. Advanced flags allow further control of how the ACE is applied to files and directories in the dataset. See the inheritance flags list for descriptions of Advanced inheritance flags. |
| Apply permissions recursively | Advanced | checkbox | Apply permissions recursively to all directories and files in the current dataset. |
| Apply permissions to child datasets | Advanced | checkbox | Apply permissions recursively to all child datasets of the current dataset. Only visible when Apply permissions recursively is set. |
| Strip ACLs | Advanced | checkbox | Set to remove all ACLs from the current dataset. ACLs are also recursively stripped from directories and child datasets when Apply permissions recursively and Apply permissions to child datasets are set. |
Additional ACEs are created by clicking ADD ACL ITEM and configuring the added fields. One ACE is required in the ACL.
See setfacl(1), nfs4_acl(5), and NFS Version 4 ACLs memo for more details about Access Control Lists, permissions, and inheritance flags. The following lists show each permission or flag that can be applied to an ACE with a brief description.
An ACE can have a variety of basic or advanced permissions:
Basic Permissions
- Read : view file or directory contents, attributes, named attributes, and ACL. Includes the Traverse permission.
- Modify : adjust file or directory contents, attributes, and named attributes. Create new files or subdirectories. Includes the Traverse permission. Changing the ACL contents or owner is not allowed.
- Traverse : Execute a file or move through a directory. Directory contents are restricted from view unless the Read permission is also applied. To traverse and view files in a directory, but not be able to open individual files, set the Traverse and Read permissions, then add the advanced Directory Inherit flag.
- Full Control : Apply all permissions.
Advanced Permissions
- Read Data : View file contents or list directory contents.
- Write Data : Create new files or modify any part of a file.
- Append Data : Add new data to the end of a file.
- Read Named Attributes : view the named attributes directory.
- Write Named Attributes : create a named attribute directory. Must be paired with the Read Named Attributes permission.
- Execute : Execute a file, move through, or search a directory.
- Delete Children : delete files or subdirectories from inside a directory.
- Read Attributes : view file or directory non-ACL attributes.
- Write Attributes : change file or directory non-ACL attributes.
- Delete : remove the file or directory.
- Read ACL : view the ACL.
- Write ACL : change the ACL and the ACL mode.
- Write Owner : change the user and group owners of the file or directory.
- Synchronize : synchronous file read/write with the server. This permission does not apply to FreeBSD clients.
Basic inheritance flags only enable or disable ACE inheritance. Advanced flags offer finer control for applying an ACE to new files or directories.
- File Inherit : The ACE is inherited with subdirectories and files. It applies to new files.
- Directory Inherit : new subdirectories inherit the full ACE.
- No Propagate Inherit : The ACE can only be inherited once.
- Inherit Only : Remove the ACE from permission checks but allow it to be inherited by new files or subdirectories. Inherit Only is removed from these new objects.
- Inherited : set when the ACE has been inherited from another dataset.
10.3. Snapshots¶
To view and manage the listing of created snapshots, use . An example is shown in Figure 10.3.1.
Note
If snapshots do not appear, check that the current time
configured in Periodic Snapshot Tasks does not conflict with
the Begin, End, and Interval
settings. If the snapshot was attempted but failed, an entry is
added to /var/log/messages. This log file can be viewed in
Shell.
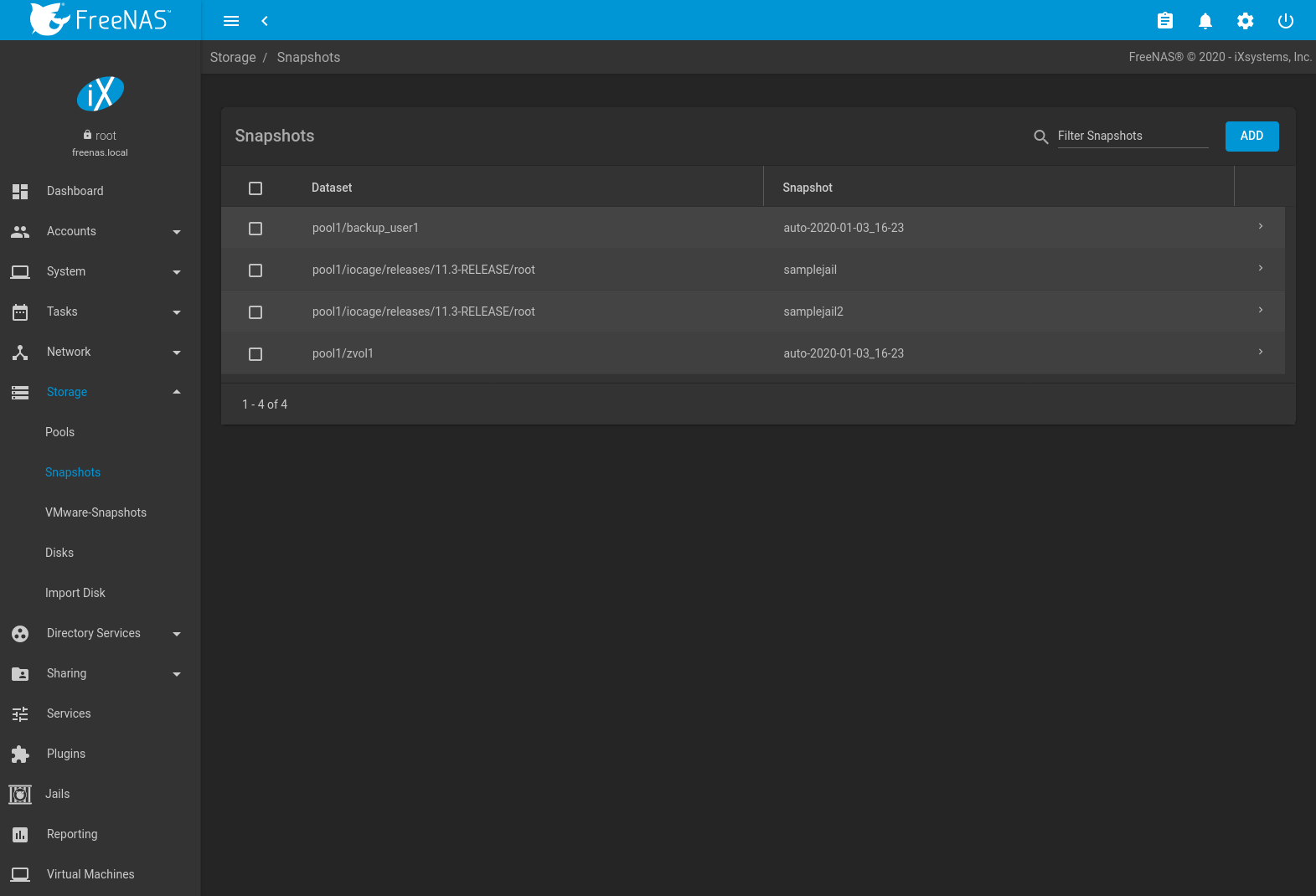
Fig. 10.3.1 Viewing Available Snapshots
Each entry in the list includes the name of the dataset and snapshot. Click (Expand) to view these options:
DATE CREATED shows the exact time and date of the snapshot creation.
USED is the amount of space consumed by this dataset and all of its descendants. This value is checked against the dataset quota and reservation. The space used does not include the dataset reservation, but does take into account the reservations of any descendent datasets. The amount of space that a dataset consumes from its parent, as well as the amount of space freed if this dataset is recursively deleted, is the greater of its space used and its reservation. When a snapshot is created, the space is initially shared between the snapshot and the filesystem, and possibly with previous snapshots. As the filesystem changes, space that was previously shared becomes unique to the snapshot, and is counted in the used space of the snapshot. Deleting a snapshot can increase the amount of space unique to, and used by, other snapshots. The amount of space used, available, or referenced does not take into account pending changes. While pending changes are generally accounted for within a few seconds, disk changes do not necessarily guarantee that the space usage information is updated immediately.
Tip
Space used by individual snapshots can be seen by running
zfs list -t snapshot from Shell.
REFERENCED indicates the amount of data accessible by this dataset, which may or may not be shared with other datasets in the pool. When a snapshot or clone is created, it initially references the same amount of space as the filesystem or snapshot it was created from, since its contents are identical.
DELETE shows a confirmation dialog. Child clones must be deleted before their parent snapshot can be deleted. While creating a snapshot is instantaneous, deleting a snapshot can be I/O intensive and can take a long time, especially when deduplication is enabled. In order to delete a block in a snapshot, ZFS has to walk all the allocated blocks to see if that block is used anywhere else; if it is not, it can be freed.
CLONE TO NEW DATASET prompts for the name of the new dataset created from the cloned snapshot. A default name is provided based on the name of the original snapshot. Click the SAVE button to finish cloning the snapshot.
A clone is a writable copy of the snapshot. Since a clone is actually a
dataset which can be mounted, it appears in the Pools screen
rather than the Snapshots screen. By default,
-clone is added to the name of a snapshot when a clone is
created.
Rollback: Clicking (Options) asks for confirmation before rolling back to the chosen snapshot state. Clicking Yes causes all files in the dataset to revert to the state they were in when the snapshot was created.
Note
Rollback is a potentially dangerous operation and causes any configured replication tasks to fail as the replication system uses the existing snapshot when doing an incremental backup. To restore the data within a snapshot, the recommended steps are:
- Clone the desired snapshot.
- Share the clone with the share type or service running on the FreeNAS® system.
- After users have recovered the needed data, delete the clone in the Active Pools tab.
This approach does not destroy any on-disk data and has no impact on replication.
A range of snapshots can be deleted. Set the left column checkboxes for each snapshot and click the Delete icon above the table. Be careful when deleting multiple snapshots.
Periodic snapshots can be configured to appear as shadow copies in newer versions of Windows Explorer, as described in Configuring Shadow Copies. Users can access the files in the shadow copy using Explorer without requiring any interaction with the FreeNAS® web interface.
To quickly search through the snapshots list by name, type a matching criteria into the Filter Snapshots text area. The listing will change to only display the snapshot names that match the filter text.
Warning
A snapshot and any files it contains will not be accessible or searchable if the mount path of the snapshot is longer than 88 characters. The data within the snapshot will be safe, and the snapshot will become accessible again when the mount path is shortened. For details of this limitation, and how to shorten a long mount path, see Path and Name Lengths.
10.3.1. Browsing a Snapshot Collection¶
All snapshots for a dataset are accessible as an ordinary hierarchical
filesystem, which can be reached from a hidden .zfs file located
at the root of every dataset. A user with permission to access that file
can view and explore all snapshots for a dataset like any other files -
from the CLI or via services
such as
, and .
This is an advanced capability which requires some command line actions
to achieve. In summary, the main changes to settings that are required
are:
- Snapshot visibility must be manually enabled in the ZFS properties of the dataset.
- In Samba auxillary settings, the veto files command must be
modified to not hide the
.zfsfile, and the setting zfsacl:expose_snapdir=true must be added.
The effect will be that any user who can access the dataset contents
will be able to view the list of snapshots by navigating to the
.zfs directory of the dataset. They will also be able to browse
and search any files they have permission to access throughout the
entire snapshot collection of the dataset.
A user’s ability to view files within a snapshot will be limited by any permissions or ACLs set on the files when the snapshot was taken. Snapshots are fixed as “read-only”, so this access does not permit the user to change any files in the snapshots, or to modify or delete any snapshot, even if they had write permission at the time when the snapshot was taken.
Note
ZFS has a zfs diff command which can list the files that have changed between any two snapshot versions within a dataset, or between any snapshot and the current data.
10.3.2. Creating a Single Snapshot¶
To create a snapshot separately from a periodic snapshot schedule, go to and click ADD.
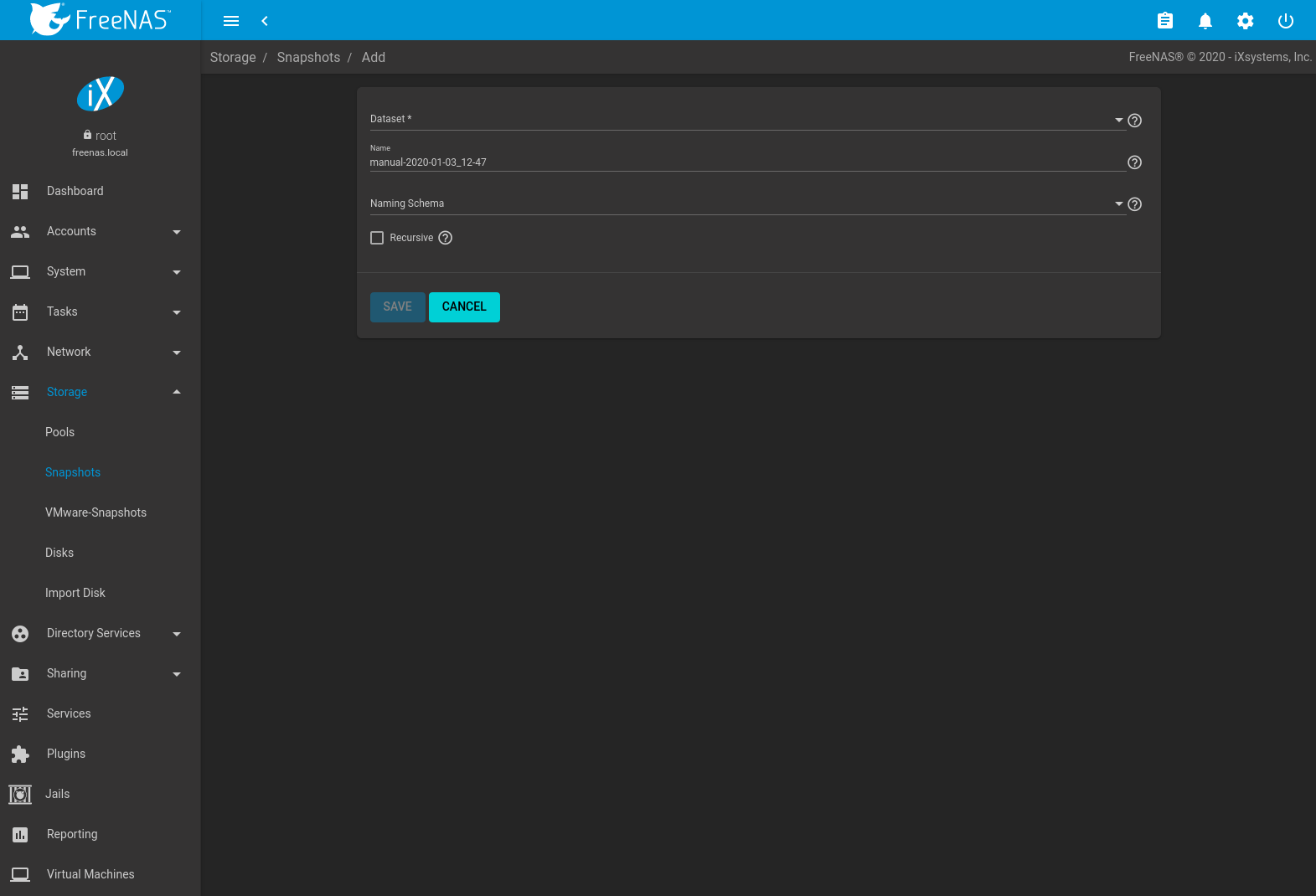
Fig. 10.3.2 Single Snapshot Options
Select an existing ZFS pool, dataset, or zvol to snapshot. To include child datasets with the snapshot, set Recursive.
The snapshot can have a custom Name or be automatically named by a Naming Schema. Using a Naming Schema allows the snapshot to be included in Replication Tasks. The Naming Schema drop-down is populated with previously created schemas from Periodic Snapshot Tasks.
10.4. VMware-Snapshots¶
is used to coordinate ZFS snapshots when using FreeNAS® as a VMware datastore. When a ZFS snapshot is created, FreeNAS® automatically snapshots any running VMware virtual machines before taking a scheduled or manual ZFS snapshot of the dataset or zvol backing that VMware datastore. Virtual machines must be powered on for FreeNAS® snapshots to be copied to VMware. The temporary VMware snapshots are then deleted on the VMware side but still exist in the ZFS snapshot and can be used as stable resurrection points in that snapshot. These coordinated snapshots are listed in Snapshots.
Figure 10.4.1 shows the menu for adding a VMware snapshot and Table 10.4.1 summarizes the available options.
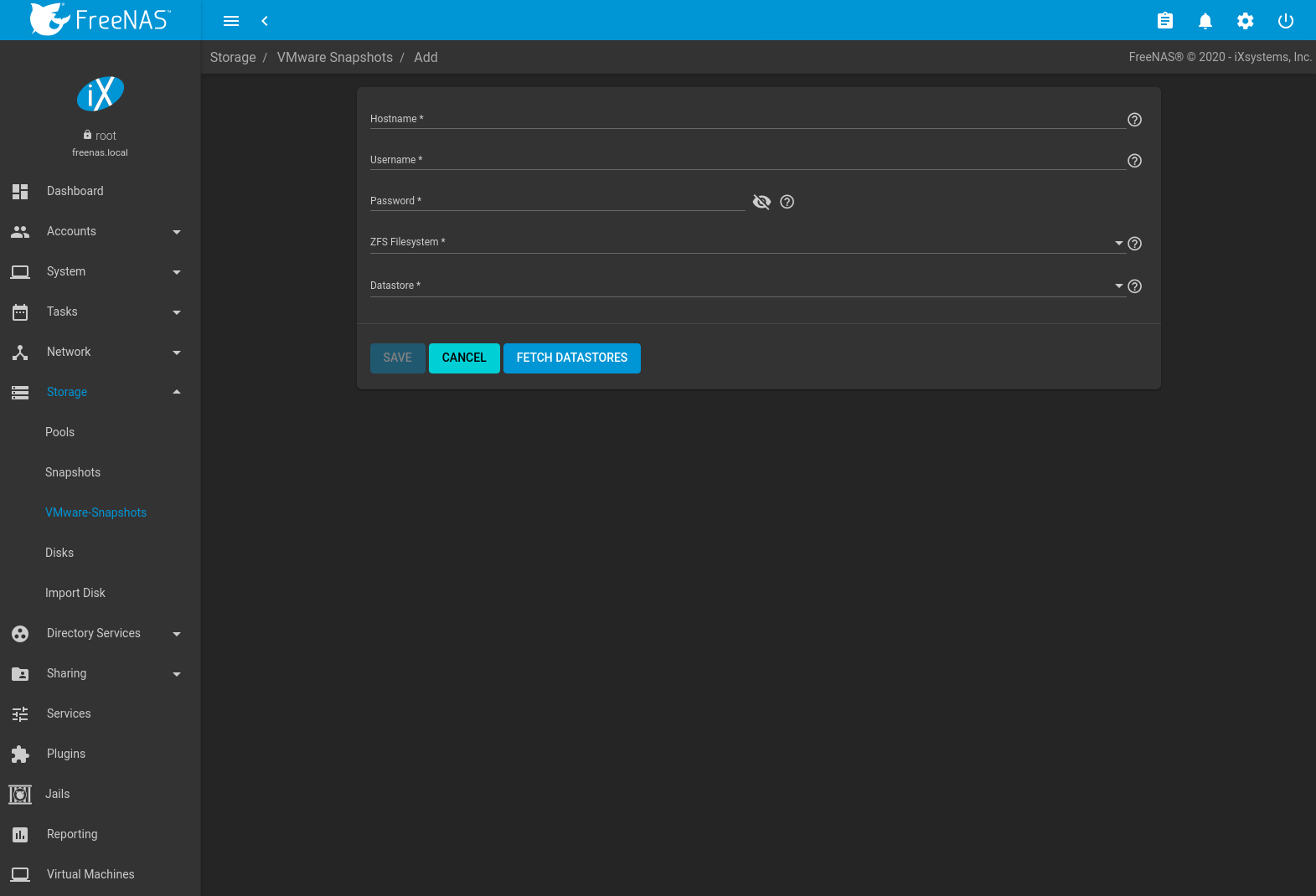
Fig. 10.4.1 Adding a VMware Snapshot
| Setting | Value | Description |
|---|---|---|
| Hostname | string | Enter the IP address or hostname of the VMware host. When clustering, use the IP address or hostname of the vCenter server for the cluster. |
| Username | string | Enter a user account name created on the VMware host. The account must have permission to snapshot virtual machines. |
| Password | string | Enter the password associated with Username. |
| ZFS Filesystem | browse button | Browse to the filesystem to snapshot. |
| Datastore | drop-down menu | After entering the Hostname, Username, and Password, click FETCH DATASTORES to populate the menu, then select the datastore to be synchronized. |
FreeNAS® connects to the VMware host after the credentials are entered. The ZFS Filesystem and Datastore drop-down menus are populated with information from the VMware host. Choosing a datastore also selects any previously mapped dataset.
10.5. Disks¶
To view all of the disks recognized by the FreeNAS® system, use . As seen in the example in Figure 10.5.1, each disk entry displays its device name, serial number, size, advanced power management settings, acoustic level settings, and whether S.M.A.R.T. tests are enabled. The pool associated with the disk is displayed in the Pool column. Unused is displayed if the disk is not being used in a pool. Click COLUMNS and select additional information to be shown as columns in the table. Additional information not shown in the table can be seen by clicking (Expand).
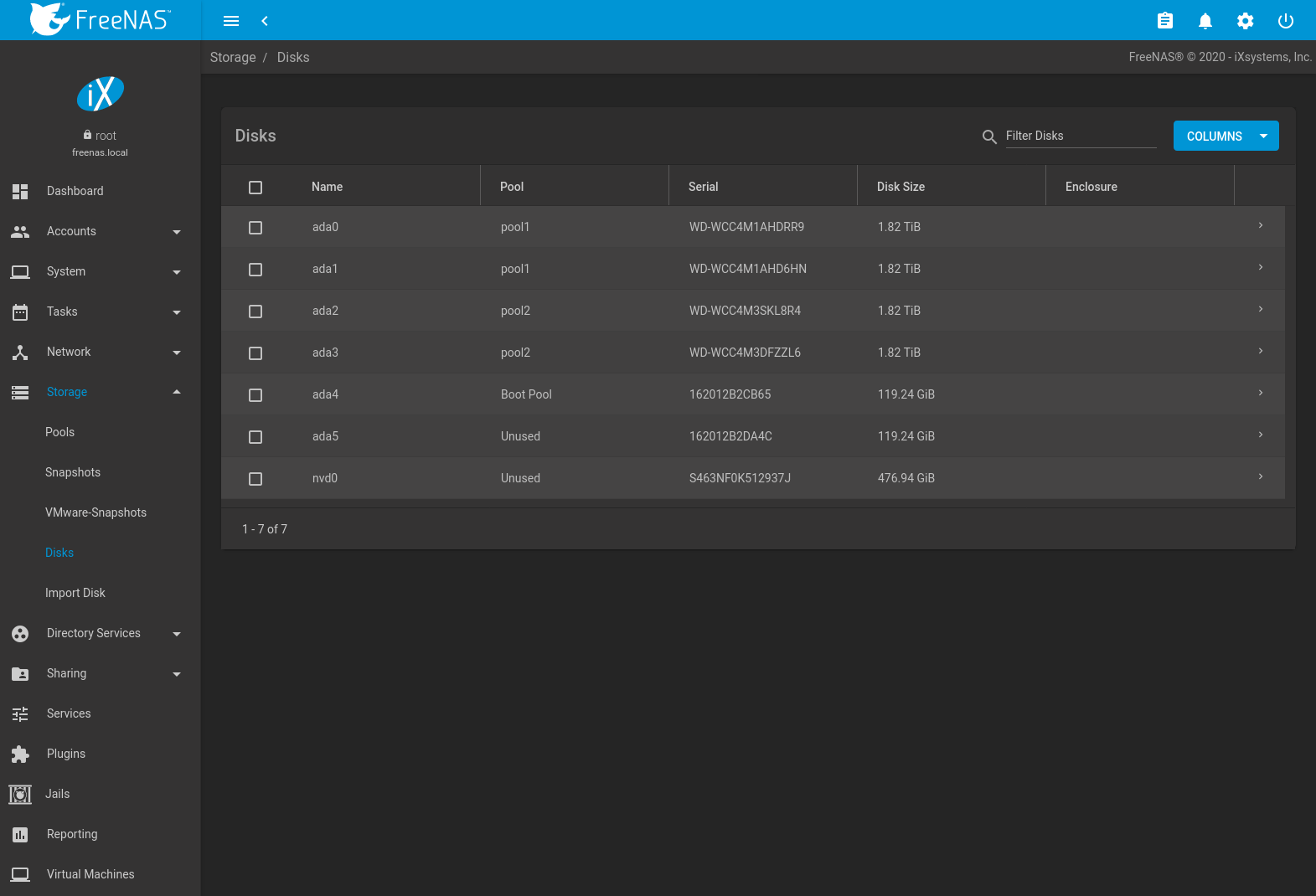
Fig. 10.5.1 Viewing Disks
To edit the options for a disk, click (Options) on a disk, then Edit to open the screen shown in Figure 10.5.2. Table 10.5.1 lists the configurable options.
To bulk edit disks, set the checkbox for each disk in the table then click (Edit Disks). The Bulk Edit Disks page displays which disks are being edited and a short list of configurable options. The Disk Options table indicates the options available when editing multiple disks.
To offline, online, or or replace the device, see Replacing a Failed Disk.
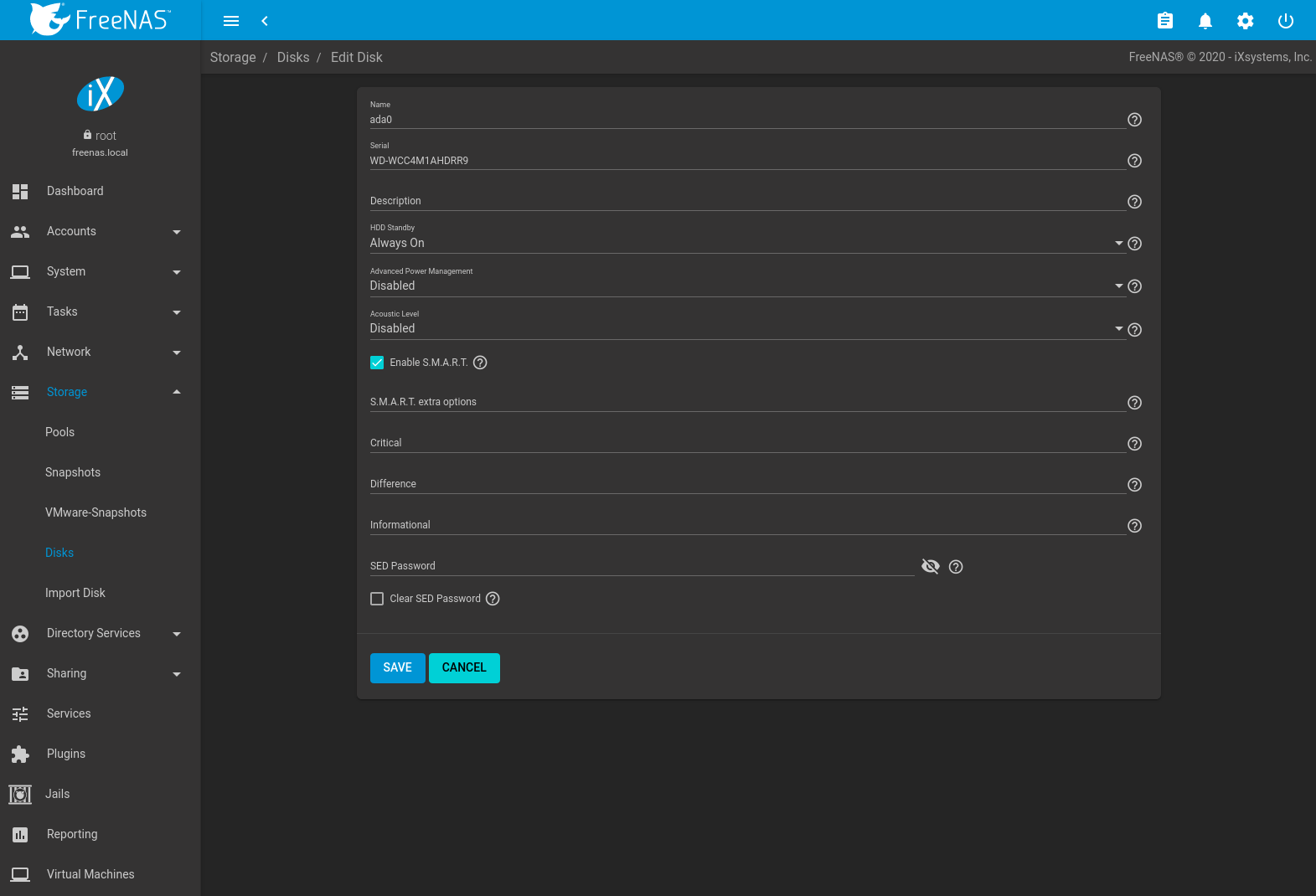
Fig. 10.5.2 Editing a Disk
| Setting | Value | Bulk Edit | Description |
|---|---|---|---|
| Name | string | This is the FreeBSD device name for the disk. | |
| Serial | string | This is the serial number of the disk. | |
| Description | string | Enter any notes about this disk. | |
| HDD Standby | drop-down menu | ✓ | Time of inactivity in minutes before the drive enters standby mode to conserve energy. This forum post shows how to determine if a drive has spun down. Temperature monitoring is disabled if the disk is set to enter standby. |
| Advanced Power Management | drop-down menu | ✓ | Select a power management profile from the menu. The default value is Disabled. |
| Acoustic Level | drop-down menu | ✓ | Default is Disabled. Other values can be selected for disks that understand AAM. |
| Enable S.M.A.R.T. | checkbox | ✓ | Enabled by default when the disk supports S.M.A.R.T. Disabling S.M.A.R.T. tests prevents collecting new temperature data for this disk. Historical temperature data is still displayed in Reporting. |
| S.M.A.R.T. extra options | string | ✓ | Enter additional smartctl(8) options. |
| Critical | string | Threshold temperature in Celsius. If the drive temperature is higher than this value, a LOG_CRIT
level log entry is created and an email is sent. 0 disables this check. |
|
| Difference | string | Report if the temperature of a drive has changed by this many degrees Celsius since the last report.
0 disables the report. |
|
| Informational | string | Report if drive temperature is at or above this temperature in Celsius. 0 disables the report. |
|
| SED Password | string | Set or change the password of this SED. This password is used instead of the global SED password in . See Self-Encrypting Drives. | |
| Clear SED Password | checkbox | Clear the SED password for this disk. |
Tip
If the serial number for a disk is not displayed in this screen, use the smartctl command from Shell. For example, to determine the serial number of disk ada0, type smartctl -a /dev/ada0 | grep Serial.
The Wipe function is used to discard an unused disk.
Warning
Ensure all data is backed up and the disk is no longer in use. Triple-check that the correct disk is being selected to be wiped, as recovering data from a wiped disk is usually impossible. If there is any doubt, physically remove the disk, verify that all data is still present on the FreeNAS® system, and wipe the disk in a separate computer.
Clicking Wipe offers several choices. Quick erases only the partitioning information on a disk, making it easy to reuse but without clearing other old data. For more security, Full with zeros overwrites the entire disk with zeros, while Full with random data overwrites the entire disk with random binary data.
Quick wipes take only a few seconds. A Full with zeros wipe of a large disk can take several hours, and a Full with random data takes longer. A progress bar is displayed during the wipe to track status.
10.5.1. Replacing a Failed Disk¶
With any form of redundant RAID, failed drives must be replaced as soon as possible to repair the degraded state of the RAID. Depending on the hardware capabilities, it might be necessary to reboot to replace the failed drive. Hardware that supports AHCI does not require a reboot.
Striping (RAID0) does not provide redundancy. Disk failure in a stripe results in losing the pool. The pool must be recreated and data stored in the failed stripe will have to be restored from backups.
Warning
Encrypted pools must have a valid passphrase to replace a failed disk. Set a passphrase and back up the encryption key using the pool Encryption Operations before attempting to replace the failed drive.
Before physically removing the failed device, go to . Select the pool name then click (Settings). Select Status and locate the failed disk. Then perform these steps:
Click (Options) on the disk entry, then Offline to change the disk status to OFFLINE. This step removes the device from the pool and prevents swap issues. Warning: encrypted disks that are set OFFLINE cannot be set back ONLINE. If the hardware supports hot-pluggable disks, click the disk Offline button and pull the disk, then skip to step 3. If there is no Offline but only Replace, the disk is already offlined and this step can be skipped.
Note
If the process of changing the disk status to OFFLINE fails with a “disk offline failed - no valid replicas” message, the pool must be scrubbed first with the Scrub Pool button in . After the scrub completes, try Offline again before proceeding.
After the disk is replaced and is showing as OFFLINE, click (Options) on the disk again and then Replace. Select the replacement disk from the drop-down menu and click the REPLACE DISK button. After clicking the REPLACE DISK button, the pool begins resilvering.
Encrypted pools require entering the encryption key passphrase when choosing a replacement disk. Clicking REPLACE DISK begins the process to reformat the replacement, apply the current pool encryption algorithm, and resilver the pool. The current pool encryption key and passphrase remains valid, but any pool recovery key file is invalidated by the replacement process. To maximize pool security, it is recommended to reset pool encryption.
After the drive replacement process is complete, re-add the replaced disk in the S.M.A.R.T. Tests screen.
To refresh the screen with updated entries, click REFRESH. If any problems occur during a disk replacement process, one of the disks can be detached. To detach a disk in the replacement process, find the disk to be replaced and click (Options) .
Figure 10.5.3 shows an example of going to and replacing a disk in an active pool.
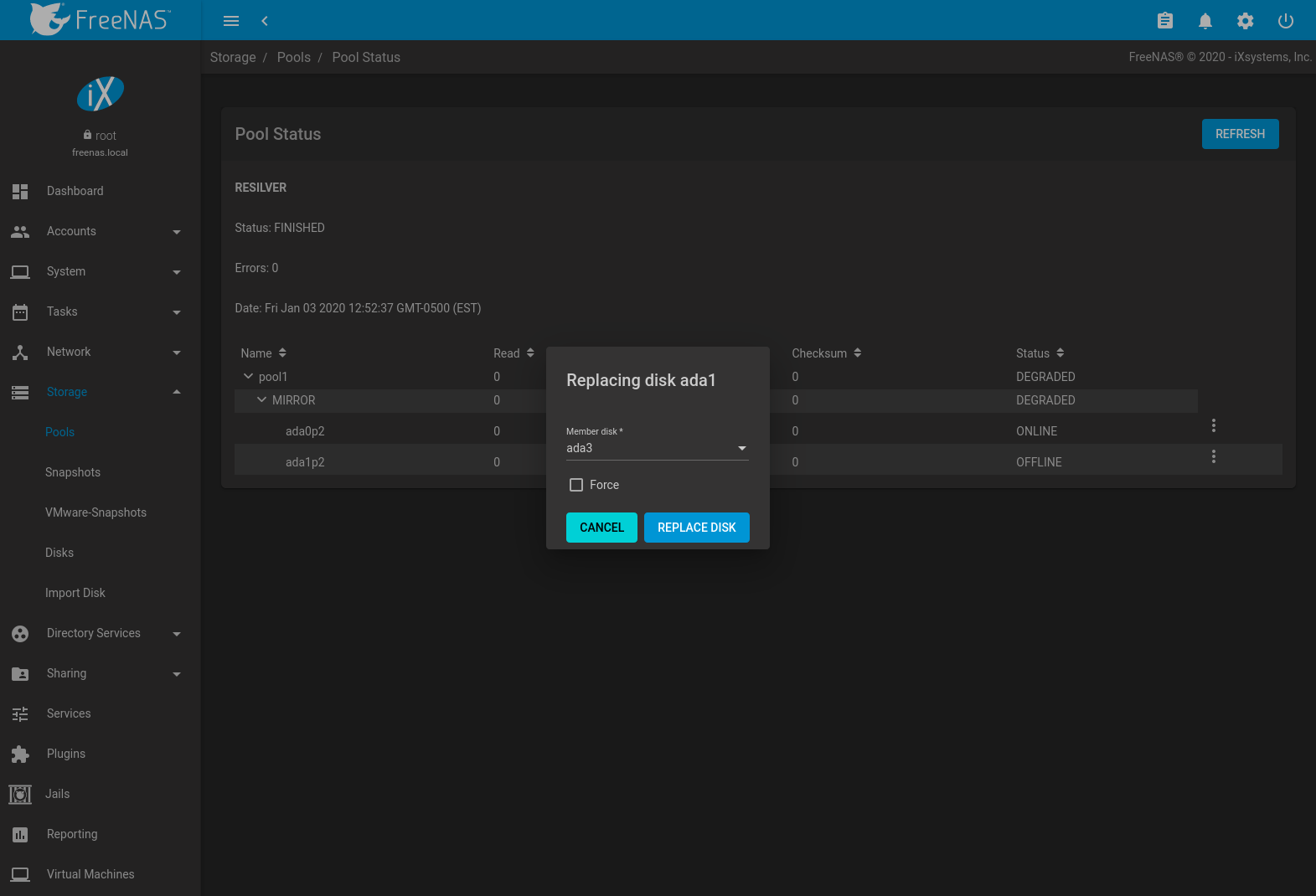
Fig. 10.5.3 Replacing a Failed Disk
After the resilver is complete, the pool status shows a Completed resilver status and indicates any errors. Figure 10.5.4 indicates that the disk replacement was successful in this example.
Note
A disk that is failing but has not completely failed can be replaced in place, without first removing it. Whether this is a good idea depends on the overall condition of the failing disk. A disk with a few newly-bad blocks that is otherwise functional can be left in place during the replacement to provide data redundancy. A drive that is experiencing continuous errors can actually slow down the replacement. In extreme cases, a disk with serious problems might spend so much time retrying failures that it could prevent the replacement resilvering from completing before another drive fails.
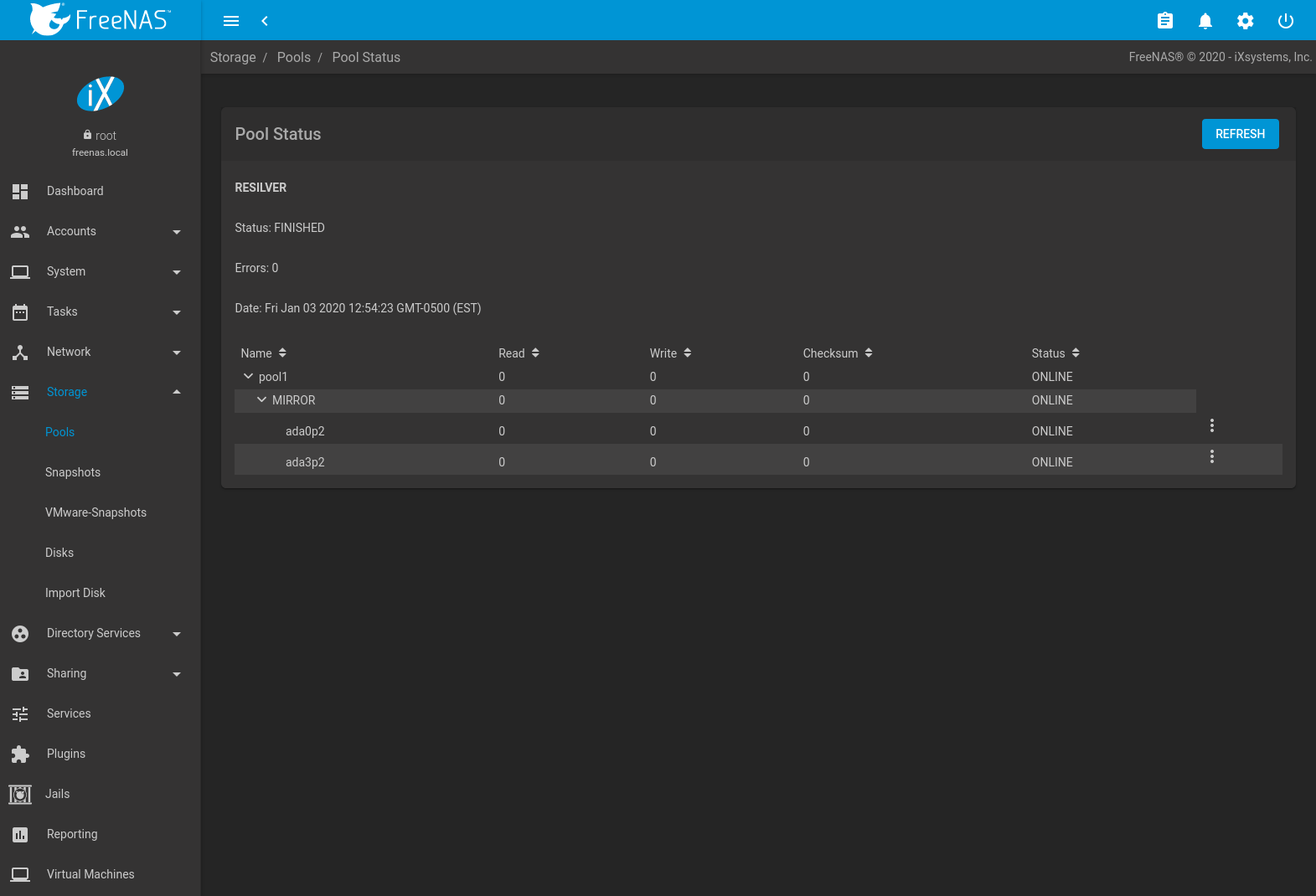
Fig. 10.5.4 Disk Replacement is Complete
10.5.1.1. Removing a Log or Cache Device¶
Added log or cache devices appear in . Clicking the device enables the Replace and Remove buttons.
Log and cache devices can be safely removed or replaced with these buttons. Both types of devices improve performance, and throughput can be impacted by their removal.
10.5.2. Replacing Disks to Grow a Pool¶
The recommended method for expanding the size of a ZFS pool is to pre-plan the number of disks in a vdev and to stripe additional vdevs from Pools as additional capacity is needed.
But adding vdevs is not an option if there are not enough unused disk ports. If there is at least one unused disk port or drive bay, a single disk at a time can be replaced with a larger disk, waiting for the resilvering process to include the new disk into the pool, removing the old disk, then repeating with another disk until all of the original disks have been replaced. At that point, the pool capacity automatically increases to include the new space.
One advantage of this method is that disk redundancy is present during the process.
Note
A pool that is configured as a stripe can only be increased by following the steps in Extending a Pool.
- Connect the new, larger disk to the unused disk port or drive bay.
- Go to .
- Select the pool and click (Settings) .
- Select one of the old, smaller disks in the pool. Click (Options) . Choose the new disk as the replacement.
The status of the resilver process is shown on the screen, or can be viewed with zpool status. When the new disk has resilvered, the old one is automatically offlined. It can then be removed from the system, and that port or bay used to hold the next new disk.
If a unused disk port or bay is not available, a drive can be replaced with a larger one as shown in Replacing a Failed Disk. This process is slow and places the system in a degraded state. Since a failure at this point could be disastrous, do not attempt this method unless the system has a reliable backup. Replace one drive at a time and wait for the resilver process to complete on the replaced drive before replacing the next drive. After all the drives are replaced and the final resilver completes, the added space appears in the pool.
10.6. Importing a Disk¶
The screen, shown in Figure 10.6.1, is used to import disks that are formatted with UFS (BSD Unix), FAT(MSDOS) or NTFS (Windows), or EXT2 (Linux) filesystems. This is a designed to be used as a one-time import, copying the data from that disk into a dataset on the FreeNAS® system. Only one disk can be imported at a time.
Note
Imports of EXT3 or EXT4 filesystems are possible in some cases, although neither is fully supported. EXT3 journaling is not supported, so those filesystems must have an external fsck utility, like the one provided by E2fsprogs utilities, run on them before import. EXT4 filesystems with extended attributes or inodes greater than 128 bytes are not supported. EXT4 filesystems with EXT3 journaling must have an fsck run on them before import, as described above.
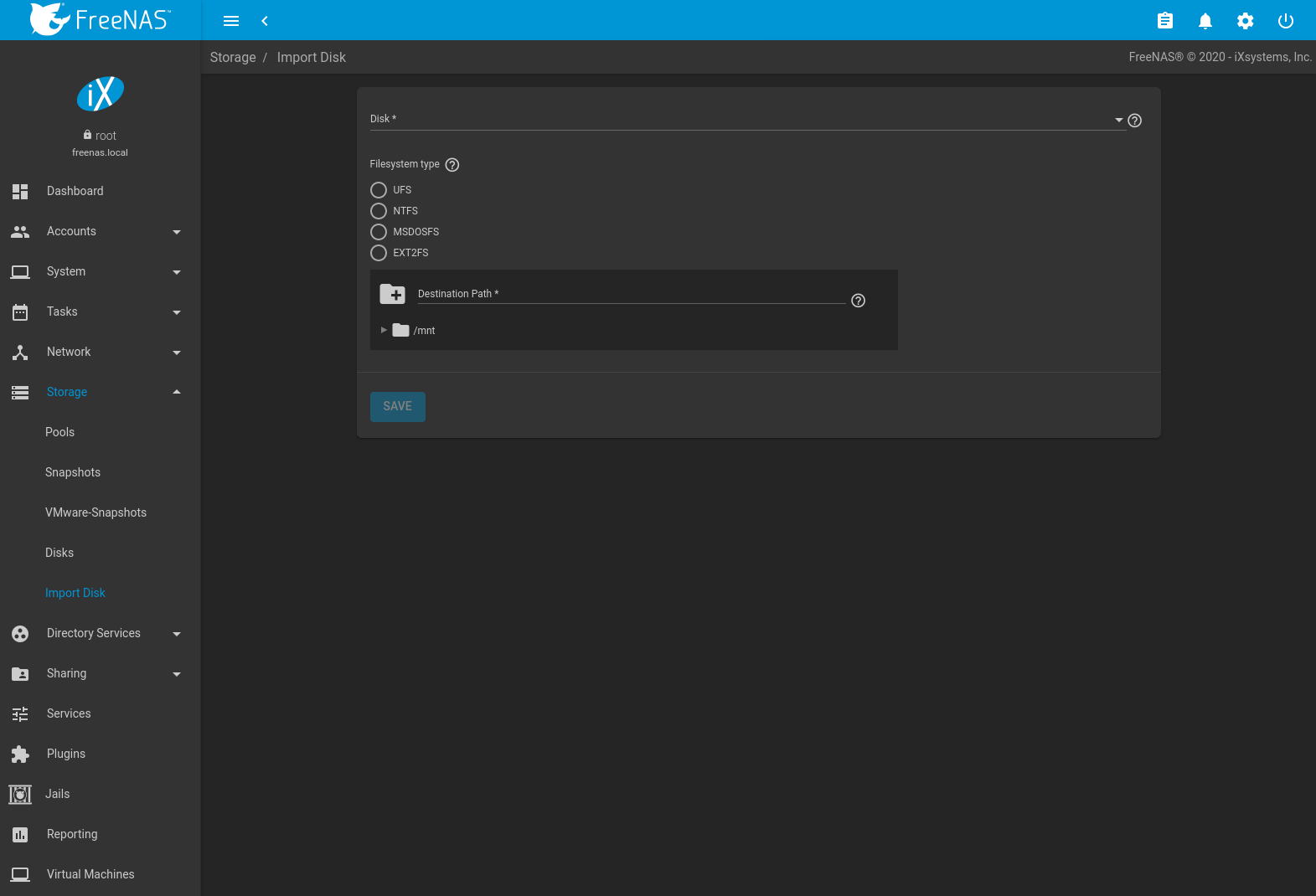
Fig. 10.6.1 Importing a Disk
Use the drop-down menu to select the disk to import, confirm the detected filesystem is correct, and browse to the ZFS dataset that will hold the copied data. If the MSDOSFS filesystem is selected, an additional MSDOSFS locale drop-down menu is displayed. Use this menu to select the locale if non-ASCII characters are present on the disk.
After clicking SAVE, the disk is mounted and its contents are copied to the specified dataset. The disk is unmounted after the copy operation completes.
After importing a disk, a dialog allows viewing or downloading the disk import log.
10.7. Multipaths¶
This option is only displayed on systems that contain multipath-capable hardware like a chassis equipped with a dual SAS expander backplane or an external JBOD that is wired for multipath.
FreeNAS® uses gmultipath(8) to provide multipath I/O support on systems containing multipath-capable hardware.
Multipath hardware adds fault tolerance to a NAS as the data is still available even if one disk I/O path has a failure.
FreeNAS® automatically detects active/active and active/passive multipath-capable hardware. Discovered multipath-capable devices are placed in multipath units with the parent devices hidden. The configuration is displayed in .
11. Overprovisioning¶
Overprovisioning SSDs can be done using the disk_resize command in the Shell. This can be useful for many different scenarios. Perhaps the most useful benefit of overprovisioning is that it can extend the life of an SSD greatly. Overprovisioning an SSD distributes the total number of writes and erases across more flash blocks on the drive. Read more about overprovisioning SSDs here.
The command to overprovision an SSD is
disk_resize device size,
where device is the device name of the SSD and size is the desired size of
the provision in GB or TB. Here is an example of the command:
disk_resize ada5 16GB. When no size is specified, it reverts the
provision back the full size of the device.
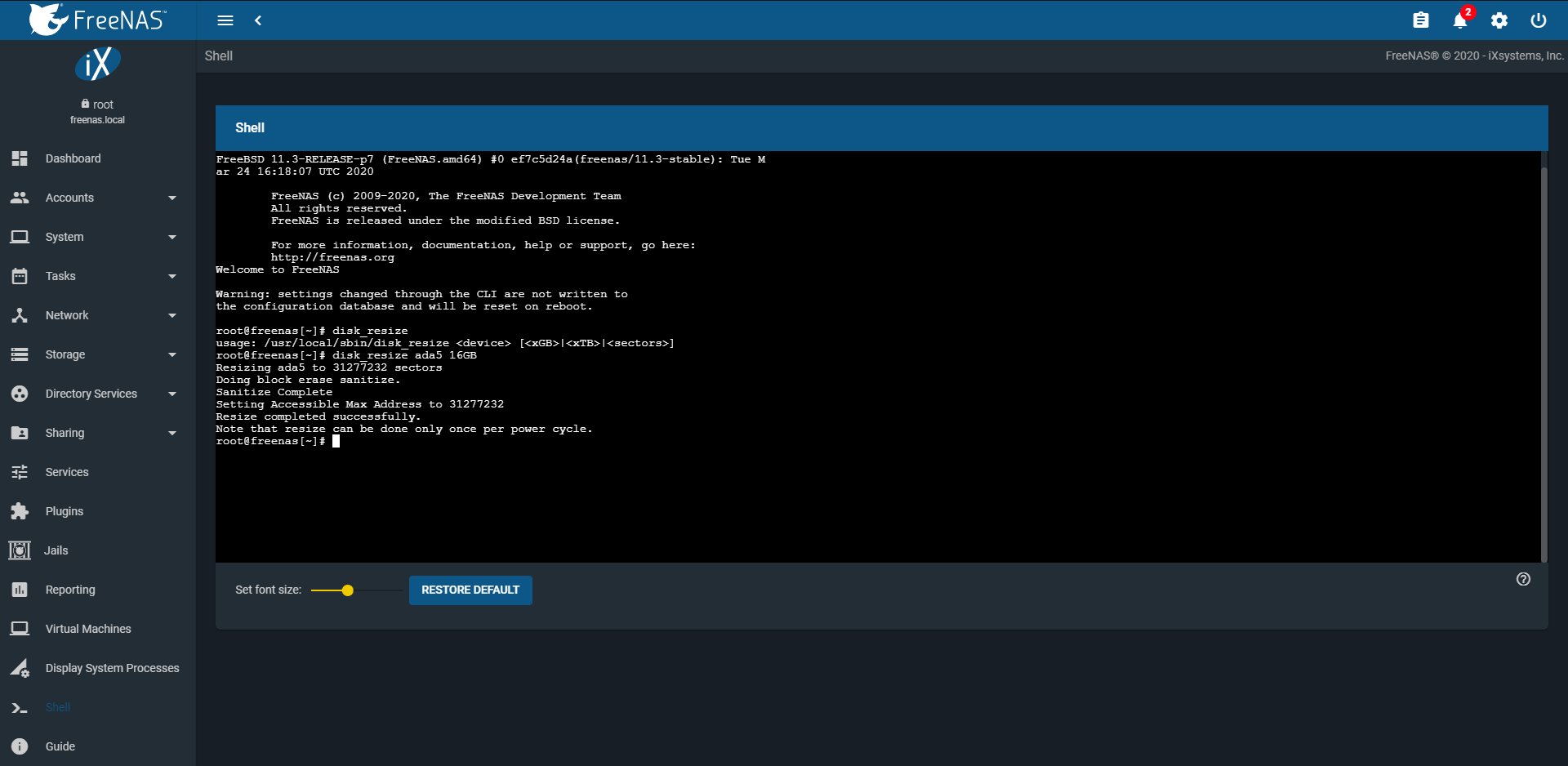
Fig. 11.1 disk_resize Command
Note
Some SATA devices may be limited to one resize per power cycle. Some BIOS may block resize during boot and require a live power cycle.